
详解如何利用amoeba(变形虫)实现mysql数据库读写分离

关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的。由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用;
amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk;
前期准备工作:
1.两个数据库,一主一从,主从同步;
- master: 172.22.10.237:3306 ;主库负责写入操作;
- slave: 10.4.66.58:3306 ; 从库负责读取操作;
- amoeba: 172.22.10.237:8066 ; 我把amoeba安装到了主库所在的服务器,当然,你也可以安装到第三台服务器上;
所有服务器操作系统均为centos7;
2.在amoeba所在的服务器上配置安装jdk;
我安装的是jdk1.8;
路径是: JAVA_HOME=/usr/local/java/jdk1.8.0_131
以上务必自己点搭建、配置好,主从正常工作,添加jdk环境变量: /etc/profile ;
安装amoeba的方式有很多,这里就不在安装上面费口舌了,我下载了amoeba-mysql-3.0.5-RC-distribution的安装包,直接解压即可使用;
解压目录: /usr/local/amoeba/
很明显 conf里是配置文件,bin里是启动程序;
刚才说到 amoeba的功能可不止读写分离,但如果只用读写分离功能的话只需要配置这几个个文件即可: conf/dbServers.xml conf/amoeba.xml 和 bin/launcher ;
conf/dbServers.xml :
`<property name="port">3306</property>
#设置Amoeba要连接的mysql数据库的端口,默认是3306
<property name="schema">testdb</property>
#设置缺省的数据库,当连接amoeba时,操作表必须显式的指定数据库名,即采用dbname.tablename的方式,不支持 use dbname指定缺省库,因为操作会调度到各个后端dbserver
<property name="user">test1</property>
#设置amoeba连接后端数据库服务器的账号和密码,因此需要在所有后端数据库上创建该用户,并授权amoeba服务器可连接
<property name="password">111111</property>
<property name="maxActive">500</property> #最大连接数,默认500
<property name="maxIdle">500</property> #最大空闲连接数
<property name="minIdle">1</property> #最新空闲连接数
<dbServer name="writedb" parent="abstractServer"> #设置一个后端可写的数据库,这里定义为writedb,这个名字可以任意命名,后面还会用到
<property name="ipAddress">172.22.10.237</property> #设置后端可写dbserver的ip
<dbServer name="slave01" parent="abstractServer"> #设置后端可读数据库
<property name="ipAddress">10.4.66.58</property>
<dbServer name="myslave" virtual="true"> #设置定义一个虚拟的dbserver,实际上相当于一个dbserver组,这里将可读的数据库ip统一放到一个组中,将这个组的名字命名为myslave
<property name="loadbalance">1</property> #选择调度算法,1表示复制均衡,2表示权重,3表示HA, 这里选择1
<property name="poolNames">slave01</property> #myslave组成员`
conf/amoeba.xml :
<property name="port">8066</property>
#设置amoeba监听的端口,默认是8066
<property name="ipAddress">127.0.0.1</property>
#配置监听的接口,如果不设置,默认监听所以的IP
# 提供客户端连接amoeba时需要使用这里设定的账号 (这里的账号密码和amoeba连接后端数据库服务器的密码无关)
<property name="user">root</property>
<property name="password">123456</property>
<property name="defaultPool">myslave</property>
#设置amoeba默认的池,这里设置为writedb
<property name="writePool">master</property>
#这两个选项默认是注销掉的,需要取消注释,这里用来指定前面定义好的俩个读写池
<property name="readPool">slave01</property>
bin/launcher :
#启动脚本,需要配置jdk环境变量;
#在注释后的第一行添加:
JAVA_HOME=/usr/local/java/jdk1.8.0_131
launcher 是启动脚本,如果不配置JAVA_HOME的话,即便你在/etc/profile中配置了环境变量也可能会报错:没有配置jdk环境变量;
还有一个配置文件: jvm.properties
#占用内存配置文件
# -Xss参数有最小值要求,必须大于228才能启动JVM
#修改:
JVM_OPTIONS="-server -Xms1024m -Xmx1024m -Xss256k -XX:PermSize=16m -XX:MaxPermSize=96m"
有经验的运维都知道,凡是和jdk沾上边的,基本都会和内存的调优有关系,amoeba也不例外;
现在可以启动了:
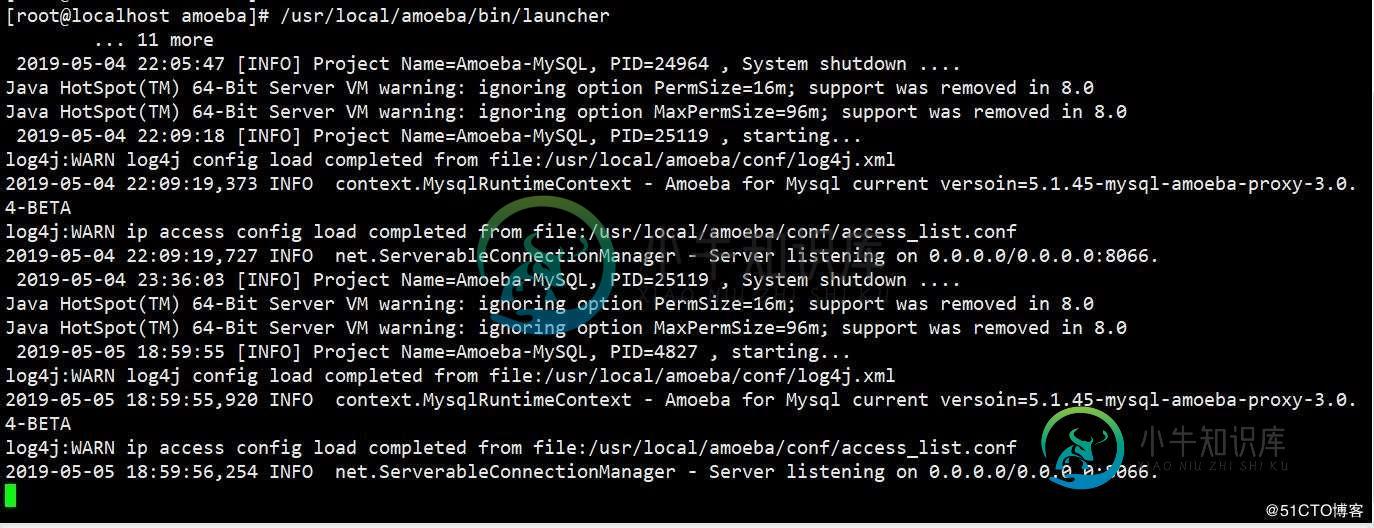
启动后就可以看到本机的8066端口:
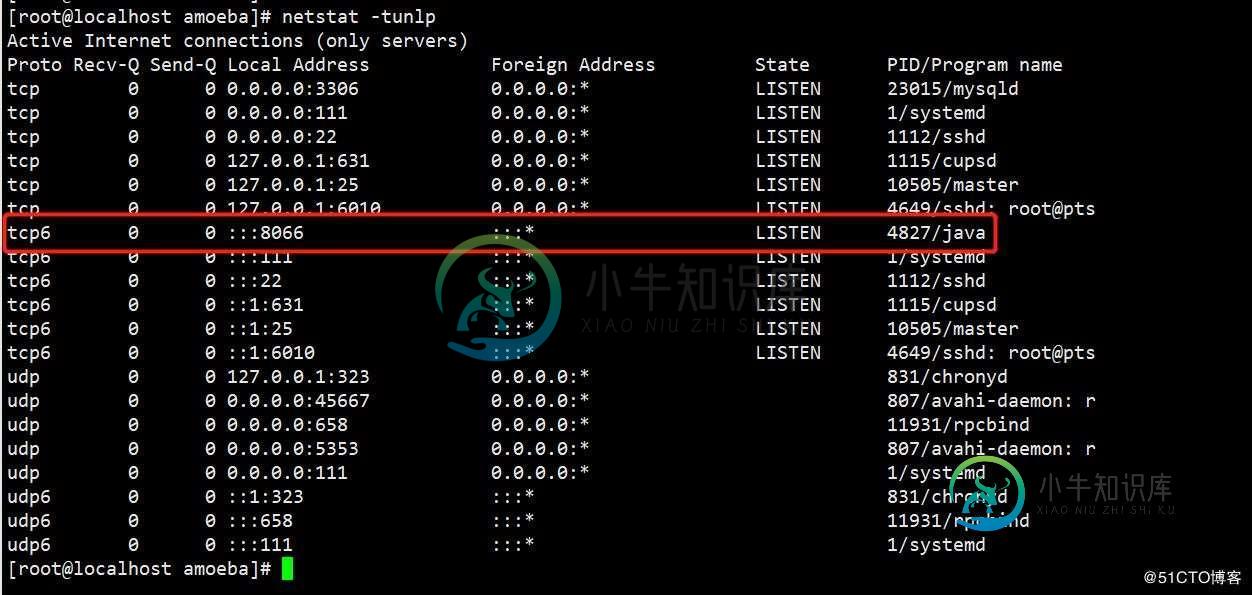
这时,你只需要通过本机ip的8066端口和你配置文件中设置的账号密码来连接数据库就行了,写入的数据都会到master里,读取的数据都会从slave中读取;
测试:
关闭master数据库,依然可以读取:执行 select 查看命令;
或者
关闭slave数据库,依然可以写入: 执行 update、inster命令;
-
本文向大家介绍MySQL 读写分离实例详解,包括了MySQL 读写分离实例详解的使用技巧和注意事项,需要的朋友参考一下 MySQL 读写分离 MySQL读写分离又一好办法 使用 com.mysql.jdbc.ReplicationDriver 在用过Amoeba 和 Cobar,还有dbware 等读写分离组件后,今天我的一个好朋友跟我讲,MySQL自身的也是可以读写分离的,因为他们提供了一个新的
-
本文向大家介绍Node.js Sequelize如何实现数据库的读写分离,包括了Node.js Sequelize如何实现数据库的读写分离的使用技巧和注意事项,需要的朋友参考一下 一、前言 在构建高并发的Web应用时,除了应用层要采取负载均衡方案外,数据库也要支持高可用和高并发性。使用较多的数据库优化方案是:通过主从复制(Master-Slave)的方式来同步数据,再通过读写分离(MySQL-Pr
-
本文向大家介绍Mybatis注解实现多数据源读写分离详解,包括了Mybatis注解实现多数据源读写分离详解的使用技巧和注意事项,需要的朋友参考一下 首先需要建立两个库进行测试,我这里使用的是master_test和slave_test两个库,两张库都有一张同样的表(偷懒,喜喜),表结构 表名 t_user | 字段名 | 类型 | 备注 | | :------: | :------: | :---
-
本文向大家介绍Yii实现MySQL多数据库和读写分离实例分析,包括了Yii实现MySQL多数据库和读写分离实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了Yii实现MySQL多数据库和读写分离的方法。分享给大家供大家参考。具体分析如下: Yii Framework是一个基于组件、用于开发大型 Web 应用的高性能 PHP 框架。Yii提供了今日Web 2.0应用开发所需要的几乎一切
-
本文向大家介绍详解使用spring aop实现业务层mysql 读写分离,包括了详解使用spring aop实现业务层mysql 读写分离的使用技巧和注意事项,需要的朋友参考一下 spring aop , mysql 主从配置 实现读写分离,接下来把自己的配置过程,以及遇到的问题记录下来,方便下次操作,也希望给一些朋友带来帮助。 1.使用spring aop 拦截机制现数据源的动态选取。 3.利用
-
本文向大家介绍使用Spring AOP实现MySQL数据库读写分离案例分析(附demo),包括了使用Spring AOP实现MySQL数据库读写分离案例分析(附demo)的使用技巧和注意事项,需要的朋友参考一下 一、前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量。 在进行数据库读写分离的时候,我们首