
Python中正则表达式的巧妙使用一文包你必掌握正则

前言
正则表达式就是从字符串中发现规律,并通过“抽象”的符号表达出来。打个比方,对于2,5,10,17,26,37这样的数字序列,如何计算第7个值,肯定要先找该序列的规律,然后用n2+1这个表达式来描述其规律,进而得到第7个值为50。对于需要匹配的字符串来说,同样把发现规律作为第一步,本文主要使用正则表达式完成字符串的查询匹配、替换匹配和分割匹配。

常用的正则符号
在进入字符串的匹配之前,先来了解一下都有哪些常用的正则符号,见下表所示:
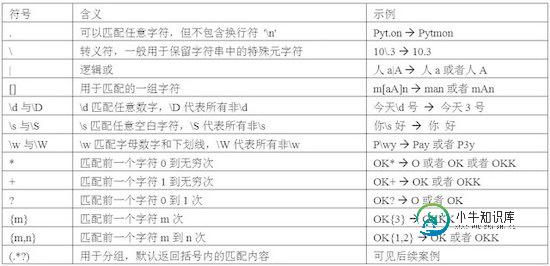
如果读者能够比较熟练地掌握上表中的内容,相信在字符串处理过程中将会游刃有余。如前文所说,本节将基于正则表达式完成字符串的查询、替换和分割操作,这些操作都需要导入re模块,并使用如下介绍的几个函数。
字符串的匹配查询
re模块中的findall函数可以对指定的字符串进行遍历匹配,获取字符串中所有匹配的子串,并返回一个列表结果。该函数的参数含义如下:
findall(pattern, string, flags=0)
pattern:指定需要匹配的正则表达式。
string:指定待处理的字符串。
flags:指定匹配模式,常用的值可以是re.I、re.M、re.S和re.X。re.I的模式是让正则表达式对大小写不敏感;re.M的模式是让正则表达式可以多行匹配;re.S的模式指明正则符号.可以匹配任意字符,包括换行符 ;re.X模式允许正则表达式可以写得更加详细,如多行表示、忽略空白字符、加入注释等。
字符串的匹配替换
re模块中的sub函数的功能是替换,类似于字符串的replace方法,该函数根据正则表达式把满足匹配的内容替换为repl。该函数的参数含义如下:
sub(pattern, repl, string, count=0, flags=0)
pattern:同findall函数中的pattern。
repl:指定替换成的新值。
string:同findall函数中的string。
count:用于指定最多替换的次数,默认为全部替换。
flags:同findall函数中的flags。
字符串的匹配分割
re模块中的split函数是将字符串按照指定的正则表达式分隔开,类似于字符串的split方法。该函数的具体参数含义如下:
split(pattern, string, maxsplit=0, flags=0)
pattern:同findall函数中的pattern。
maxsplit:用于指定最大分割次数,默认为全部分割。
string:同findall函数中的string。
flags:同findall函数中的flags。
实战案例
如果上面的函数和参数含义都已经掌握了,还需要进一步通过案例加强理解,接下来举例说明上面的三个函数:
# 导入用于正则表达式的re模块
import re
# 取出字符串string8中所有的天气状态
string8 = "{ymd:'2018-01-01',tianqi:'晴',aqiInfo:'轻度污染'},{ymd:'2018-01-02',tianqi:'阴~小雨',aqiInfo:'优'},{ymd:'2018-01-03',tianqi:'小雨~中雨',aqiInfo:'优'},{ymd:'2018-01-04',tianqi:'中雨~小雨',aqiInfo:'优'}"
# 基于正则表达式使用findall函数
print(re.findall("tianqi:'(.*?)'", string8))
# 取出string9中所有含O字母的单词
string9 = 'Together, we discovered that a free market only thrives when there are rules to ensure competition and fair play, Our celebration of initiative and enterprise'
# 基于正则表达式使用findall函数
print(re.findall('w*ow*',string9, flags = re.I))
# 将string10中的标点符号、数字和字母删除
string10 = '据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。'
# 基于正则表达式使用sub函数
print(re.sub('[,。、a-zA-Z0-9()]','',string10))
# 将string11中的每个子部分内容分割开
string11 = '2室2厅 | 101.62平 | 低区/7层 | 朝南
上海未来 - 浦东 - 金杨 - 2005年建'
# 基于正则表达式使用split函数
split = re.split('[-|
]', string11)
print(split)
# 分割结果的清洗
split_strip = [i.strip() for i in split]
print(split_strip)
out:
['晴', '阴~小雨', '小雨~中雨', '中雨~小雨']
['Together', 'discovered', 'only', 'to', 'competition', 'Our', 'celebration', 'of']
据悉这次发运的台蒸汽冷凝罐属于国际热核聚变实验堆项目的核二级压力设备先后完成了压力试验真空试验氦气检漏试验千斤顶试验吊耳载荷试验叠装试验等验收试验
['2室2厅 ', ' 101.62平 ', ' 低区/7层 ', ' 朝南 ', ' 上海未来 ', ' 浦东 ', ' 金杨 ', ' 2005年建']
['2室2厅', '101.62平', '低区/7层', '朝南', '上海未来', '浦东', '金杨', '2005年建']
如上结果所示,在第一个例子中通过正则表达式"tianqi:'(.*?)'"实现目标数据的获取,如果不使用括号的话,就会产生类似"tianqi:'晴'", "tianqi:'阴~小雨'"这样的值,所以,加上括号就是为了分组,且仅返回组中的内容;
第二个例子并没有将正则表达式写入圆括号,如果写上圆括号也是返回一样的结果,所以findall就是用来返回满足匹配条件的列表值,如果有括号,就仅返回括号内的匹配值;
第三个例子使用替换的方法,将所有的标点符号换为空字符,进而实现删除的效果;
第四个例子是对字符串的分割,如果直接按照正则 '[,。、a-zA-Z0-9()]' 分割的话,返回的结果中包含空字符,如 '2室2厅' 后面就有一个空字符。为了删除列表中每个元素的首尾空字符,使用了列表表达式,并且结合字符串的strip方法完成空字符的压缩。
总结
以上所述是小编给大家介绍的Python中正则表达式的巧妙使用一文包你必掌握正则,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
-
本文向大家介绍教你学会使用Python正则表达式,包括了教你学会使用Python正则表达式的使用技巧和注意事项,需要的朋友参考一下 今天写爬虫偶然想到了初学正则表达式时候,看过一篇文章非常不错。检索一下还真的找到了。 re模块 re.search 经常用match = re.search(pat, str)的形式。因为有可能匹配不到,所以re.search()后面一般用if statement。
-
1. 正则表达式 1.1 简介 正则表达式 (regular expression) 描述了一种字符串匹配的模式 (pattern),例如: 模式 ab+c 可以匹配 abc、abbc、abbbc 代表前面的字符出现 1 次或者多次 模式 ab*c 可以匹配 ac、abc、abbc ? 代表前面的字符出现 0 次或者多次 模式 ab?c 可以匹配 ac、abc ? 代表前面的字符出现 0 次或者
-
行动时刻 - 使用正则表达式 Unlang允许在条件检查中进行正则表达式计算。这些通常是Posix正则表达式。运算符=〜和!〜与正则表达式相关联。为了简单的概念证明,我们将修改上一个练习: 1.编辑FreeRADIUS配置目录下的sites-available / default虚拟服务器,并在该部分顶部的post-auth部分中添加以下内容: if(request:Framed-Protocol
-
序:世界上信息非常多,而我们关注的信息有限。假如我们希望只提取出关注的数据,此时可以通过一些表达式进行提取,正则表达式就是其中一种进行数据筛选的表达式。 正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。 正则表达式通常被用来匹配、检索、替换和分割那些符合某个模式(规则)的文本。 Python 自1.5版本起
-
sorter: "${$(...props)=>{timeSort(createTime)}$}$", ..$}$"."${$.. 希望结果 :sorter: (...props)=>{timeSort(createTime)}, ..$}$"."${$.. 规则: "${$ 和 $}$" 是一对,将他们替换为空。
-
昨天,我需要向正则表达式添加一个文件路径,创建一个如下所示的模式: 一开始正则表达式不匹配,因为包含几个正则表达式特定的符号,如 或 。作为快速修复,我将它们替换为 和 . 与 . 然而,我问自己,是否没有一种更可靠或更好的方法来清除正则表达式特定符号中的字符串。 Python 标准库中是否支持此类功能? 如果没有,您是否知道一个正则表达式来识别所有正则表达式并通过替代品清理它们?