
详解R语言中生存分析模型与时间依赖性ROC曲线可视化

R语言简介
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归。但是,流行病学研究中感兴趣的结果通常是事件发生时间。使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型。
时间依赖性ROC定义
令 Mi为用于死亡率预测的基线(时间0)标量标记。 当随时间推移观察到结果时,其预测性能取决于评估时间 t。直观地说,在零时间测量的标记值应该变得不那么相关。因此,ROC测得的预测性能(区分)是时间t的函数 。
累积病例
累积病例/动态ROC定义了在时间t 处的阈值c处的 灵敏度和特异性, 如下所示。
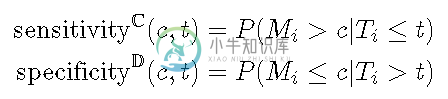
累积灵敏度将在时间t之前死亡的视为分母(疾病),而将标记值高于 c 的作为真实阳性(疾病阳性)。动态特异性将在时间t仍然活着作为分母(健康),并将标记值小于或等于 c 的那些作为真实阴性(健康中的阴性)。将阈值 c 从最小值更改为最大值会在时间t处显示整个ROC曲线 。
新发病例
新发病例ROC1在时间t 处以阈值 c定义灵敏度和特异性, 如下所示。
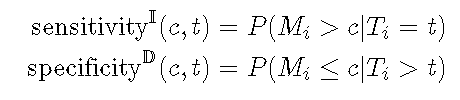
累积灵敏度将在时间t处死亡的人 视为分母(疾病),而将标记值高于 Ç 的人视为真实阳性(疾病阳性)。
数据准备
我们以数据 包中的dataset3survival为例。事件发生的时间就是死亡的时间。Kaplan-Meier图如下。
## 变成data_frame
data <- as_data_frame(data)
## 绘图
plot(survfit(Surv(futime, fustat) ~ 1,
data = data)
可视化结果:
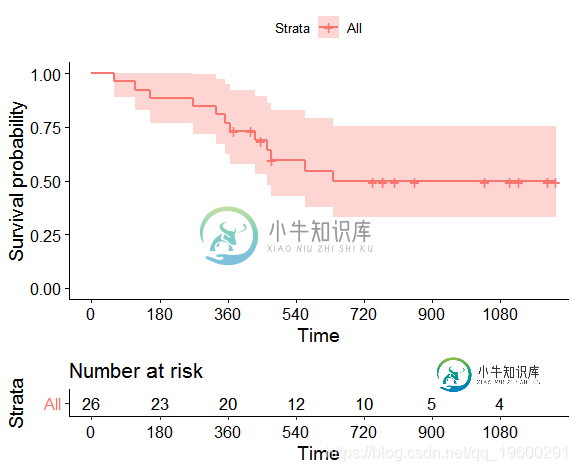
在数据集中超过720天没有发生任何事件。
## 拟合cox模型 coxph(formula = Surv(futime, fustat) ~ pspline(age, df = 4) + ##获得线性预测值 predict(coxph1, type = "lp")
累积病例
实现了累积病例
## 定义一个辅助函数,以在不同的时间进行评估
ROC_hlp <- function(t) {
survivalROC(Stime
status
marker
predict.time = t,
method = "NNE",
span = 0.25 * nrow(ovarian)^(-0.20))
}
## 每180天评估一次
ROC_data <- data_frame(t = 180 * c(1,2,3,4,5,6)) %>%
mutate(survivalROC = map(t, survivalROC_helper),
## 提取AUC
auc = map_dbl(survivalROC, magrittr::extract2, "AUC"),
## 在data_frame中放相关的值
df_survivalROC = map(survivalROC, function(obj) {
## 绘图
ggplot(mapping = aes(x = FP, y = TP)) +
geom_point() +
geom_line() +
facet_wrap( ~ t) +
可视化结果:
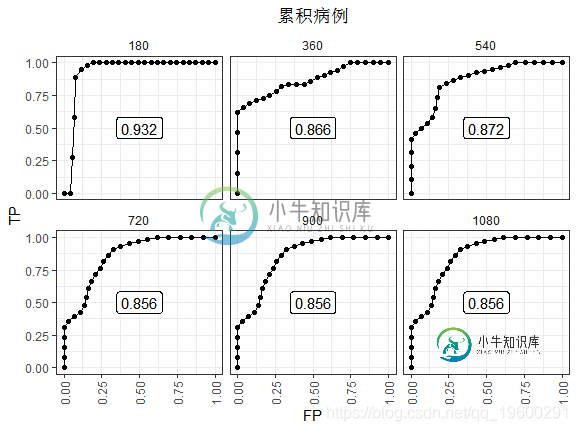
180天的ROC看起来是最好的。因为到此刻为止几乎没有事件。在最后观察到的事件(t≥720)之后,AUC稳定在0.856。这种表现并没有衰退,因为高风险分数的人死了。
新发病例
实现新发病例
## 定义一个辅助函数,以在不同的时间进行评估
## 每180天评估一次
## 提取AUC
auc = map_dbl(risksetROC, magrittr::extract2, "AUC"),
## 在data_frame中放相关的值
df_risksetROC = map(risksetROC, function(obj) {
## 标记栏
marker <- c(-Inf, obj[["marker"]], Inf)
## 绘图
ggplot(mapping = aes(x = FP, y = TP)) +
geom_point() +
geom_line() +
geom_label(data = risksetROC_data %>% dplyr::select(t,auc) %>% unique,
facet_wrap( ~ t) +
可视化结果:
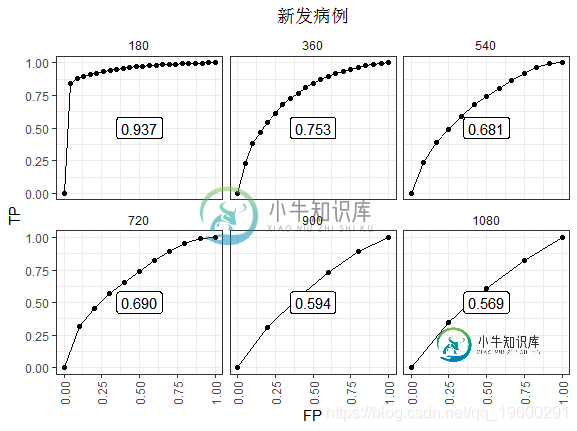
这种差异在后期更为明显。最值得注意的是,只有在每个时间点处于风险集中的个体才能提供数据。所以数据点少了。表现的衰退更为明显,也许是因为在那些存活时间足够长的人中,时间零点的风险分没有那么重要。一旦没有事件,ROC基本上就会趋于平缓。
结论
总之,我们研究了时间依赖的ROC及其R实现。累积病例ROC可能与风险 (累积发生率)预测模型的概念更兼容 。新发病例ROC可用于检查时间零标记在预测后续事件时的相关性。
参考
Heagerty,Patrick J. and Zheng,Yingye, Survival Model Predictive Accuracy and ROC Curves,Biometrics,61(1),92-105(2005). doi:10.1111 / j.0006-341X.2005.030814.x.
到此这篇关于详解R语言中生存分析模型与时间依赖性ROC曲线可视化的文章就介绍到这了,更多相关R语言生存分析曲线可视化内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
主要内容:安装包,示例,应用Surv()和survfit()函数生存分析涉及预测特定事件发生的时间。 它也被称为失败时间分析或分析死亡时间。 例如预测癌症患者的生存天数或预测机械系统出现故障的时间。 R中的软件包:用于进行生存分析。该包中含有函数,它将输入数据作为R公式,并在所选变量中创建一个生存对象进行分析。然后使用函数来创建分析图。 安装包 语法 在R中创建生存分析的基本语法是 - 以下是使用的参数的描述 - time - 是直到事件发生的后续时间。 ev
-
主要内容:语法,示例,不同的时间间隔,多时间系列时间序列是一系列数据点,其每个数据点与时间戳相关联。 一个简单的例子就是股票在某一天不同时间点的股票价格。另一个例子是一年中不同月份某个地区的降雨量。R语言使用许多功能来创建,操纵和绘制时间序列数据。时间序列的数据存储在称为时间序列对象的R对象中。 它也是一个R数据对象,如向量或数据帧。 时间序列对象是通过使用函数创建的。 语法 时间序列分析所使用的函数的基本语法是 - 以下是使用的参数的描述 -
-
主要内容:建立回归的步骤回归分析是一个广泛使用的统计工具,用于建立两个变量之间的关系模型。 这些变量之一称为预测变量,其值通过实验收集。 另一个变量称为响应变量,其值来自预测变量。 在线性回归中,这两个变量通过一个等式相关联,其中这两个变量的指数(幂)是。数学上,当绘制为图形时,线性关系表示直线。任何变量的指数不等于的非线性关系产生曲线。 线性回归的一般数学方程为 - 以下是使用的参数的描述 - y - 是响应变量。 x
-
我训练了一名CNN,将图像分为5类。但是,当我试图绘制每个类别相对于其他类别的曲线时,所有5个类别几乎都有一条对角线曲线,其约为0.5。我不知道出了什么问题。 该模型的准确率应该在86%左右。 代码如下: "prediction_prob"变量包含: 而“正确”变量包含每个测试图像的正确标签: 我想我遵循了网站上提到的内容。 生成的tpr[i]和fpr[i]变量变为线性相关,因此AUC变为0.5
-
本文向大家介绍解析C语言与C++的编译模型,包括了解析C语言与C++的编译模型的使用技巧和注意事项,需要的朋友参考一下 首先简要介绍一下C的编译模型: 限于当时的硬件条件,C编译器不能够在内存里一次性地装载所有程序代码,而需要将代码分为多个源文件,并且分别编译。并且由于内存限制,编译器本身也不能太大,因此需要分为多个可执行文件,进行分阶段的编译。在早期一共包括7个可执行文件:cc(调用其它可执行文
-
主要内容:ANCOVA分析,比较两个模型我们使用回归分析来创建描述预测变量变量对响应变量的影响的模型。有时,如果我们有类似于是/否或男/女等值的分类变量,简单回归分析为分类变量的每个值提供多个结果。在这种情况下,可以通过使用分类变量和预测变量来研究分类变量的影响,并比较分类变量的每个级别的回归线。 这样的分析被称为协方差分析,也称为ANCOVA。 输入数据 从R提供的数据集创建一个包含字段,和的数据框。 这里我们将作为响应变量,将作为预