
tensorflow之并行读入数据详解

最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考。
并行读入数据主要分
1. 创建文件名列表
2. 创建文件名队列
3. 创建Reader和Decoder
4. 创建样例列表
5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要批列表来分批进行数据的组织,提取)
其具体流程如下:
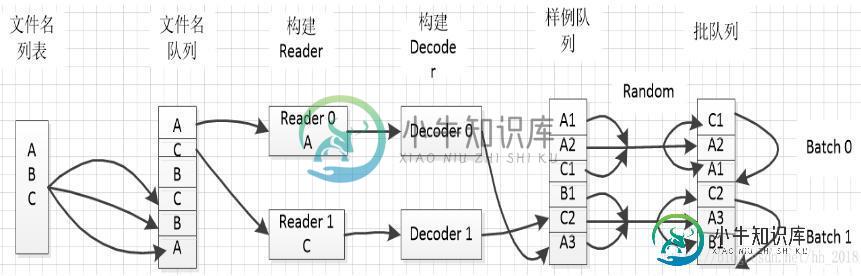
一、 文件名列表:
文件名列表是一个list类型的数据,里面的内容是需要用的数据文件名。可以使用常规的python语法入:[file1, file2]。也可以使用tf.train.match_filename_once方法通过匹配输入。
二、文件名队列
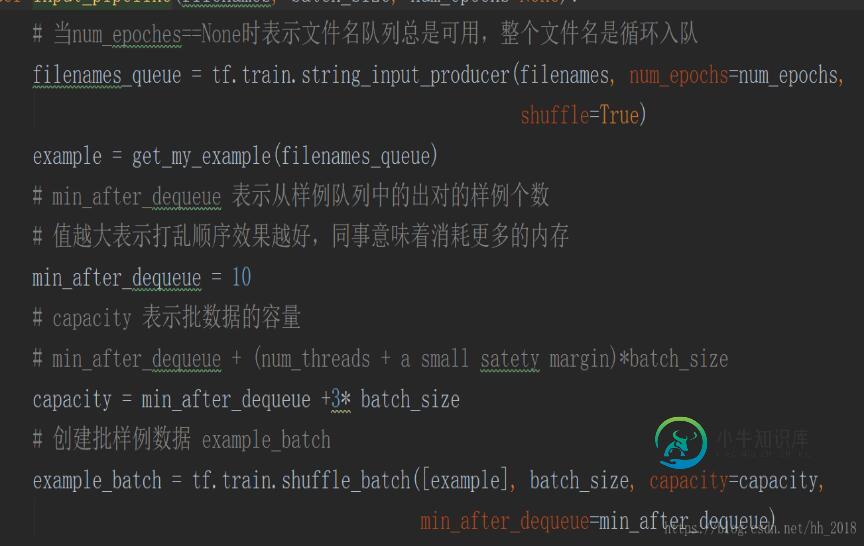
一般使用tf.train.string_input_producer的方法创建文件名队列。该方法传入的是一个文件名列表,输出的是一个先进先出队列。在该方法中存在两个重要参数,num_epochs和shuffle。num_epochs表示列表遍历的次数,主要是由于有时候训练模型需要反复的遍历数据集便于更新模型参数,默认情况下是None(循环遍历)。shuffle表示是否随机遍历,默认情况下是true,表示数据会随机输入队列,当想顺序读入数据时shuffle设置为false。至于其他的capacity表示列表的容量,shared_name表示共享时的名字。
三、Reader和Decoder
Reader的功能是读取数据记录,Decoder的功能是将数据的记录转化为张量格式。在使用时需要先创建输入数据文件对应的Reader,然后从文件名队列中取出文件名,在调用Reader.read的方法返回一个类似于(输入文件名,数据记录)的元组。最后使用Decoder方法将每一列数据都转化为张量的形式。
四、批队列
批队列可以在构建图之前事先构建好,样例队列需要在图中直接产生不用直接预定义。所以先介绍批队列的构建方式。批队列主要是样例打包聚集成批数据,能供模型训练使用。一般是使用tf.train.shuffle_batch和tf.train.batch的方法构建。可以控制批的大小(一次性读入的 数据大小),线程个数,然后在图中直接调用。

五、样例队列
样例队列的创建方式是隐式的,一般在图中为了计算任务顺利的输入数据,我们一般使用tf.train.start_queue_runners方法启动所有的入队操作所需的线程,此时会自动执行所有的文件名入队操作和文件名队列的操作,执行样例队列入队和样例队列的操作。这些都是在后台产生的。
六、线程协调器
并行读取数据离不开多线程操作,多线程操作离不开线程调节器。tensorflow使用tf.train.Coordinatior方法创建管理多线程生命周期的调节器。调节器的工作原理比较简单,它监控Tensoflow后台的所有线程,当某一个线程出现异常时,它的should_stop方法返回true,最后调用request_stop终止所有的线程。但是要注意我们在使用线程调节器之前一定要调用tf.local_variables_initializer方法进行初始化。
七、读入数据类型
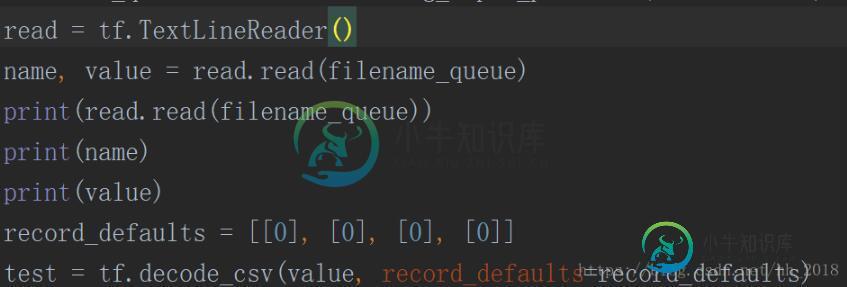
tensorflow读入的数据类型可以使csv,TFRecord和自由格式文件。CSV的读取直接调用tf.TextLineReader构建Reader,再调用tf.decoder_csv的方法对文件进行解码变为张量。
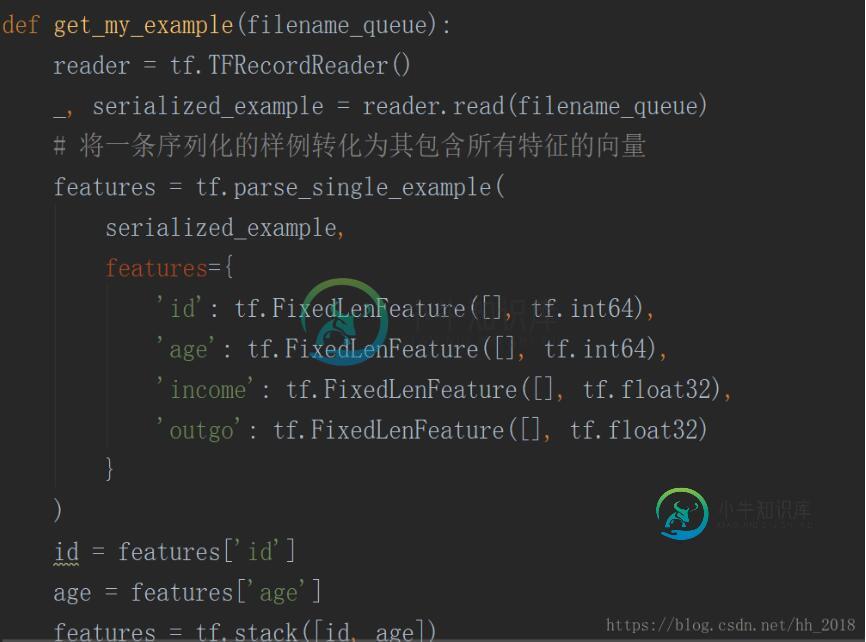
TFRecoder是tensorflow标准的输入格式,它是通过protocolBuffer构建的存储数据记录的结构。该数据结构分明,一个样例中包含一组特征Features,一个Features又包含多个特征向量feature。其在读取的时候主要使用tf.TFRecoderReader的方法构建Reader,在使用read的方法读出元组。接着对元组中的value采用tf.parse_single_example()方法进行解析。再解析的时候需要传入features参数,该参数要和构造该文件时输入的字典型变量保持一致(key,value)。key和输入的key一致,value是一个表示该key对应的维度和类型的定西,用tf.FixedLenFeature函数构造,该函数传入参数表示特征形状和特征值的类型。具体如下:
自由格式是指用户自定义的二进制文件,他存储的对象是字符串,每条记录都是一个固定长度的字节块。再读入的时候首先要使用tf.FixedLengthRecoderReader的方法读取对应的二进制文件,然后使用tf.decode_raw的方法将字符串转化为uint8类型的张量。
八、整体代码
具体的相关码如下:
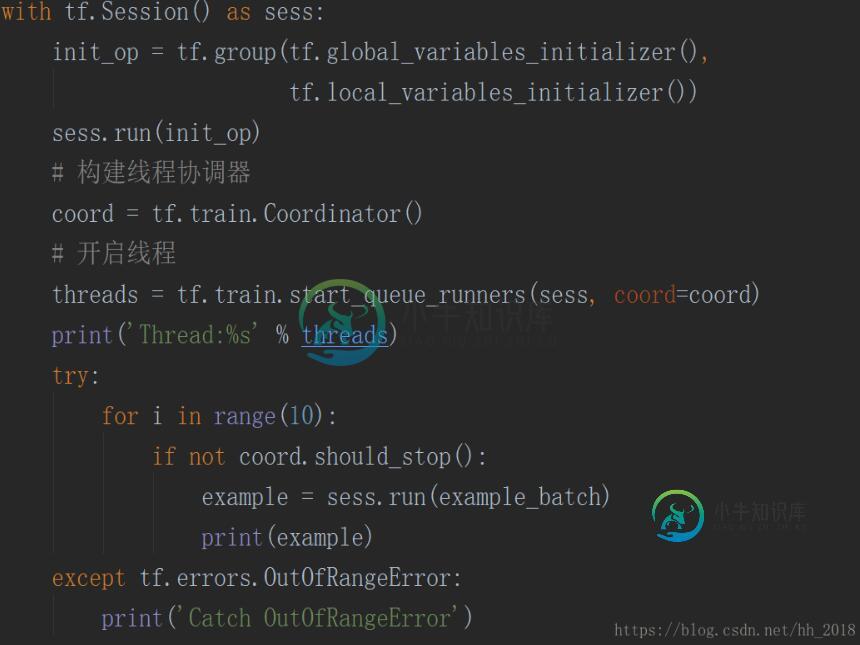
以上这篇tensorflow之并行读入数据详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍详解tensorflow载入数据的三种方式,包括了详解tensorflow载入数据的三种方式的使用技巧和注意事项,需要的朋友参考一下 Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端。 Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道Te
-
我试图从mysql读取数据,并将其写回s3中的parquet文件,具体分区如下: 我的问题是,它只打开一个到mysql的连接(而不是4个),并且在从mysql获取所有数据之前,它不会写入parquert,因为mysql中的表很大(100M行),进程在OutOfMemory上失败。 有没有办法将Spark配置为打开多个到mysql的连接并将部分数据写入镶木地板?
-
本文向大家介绍Python实现数据库并行读取和写入实例,包括了Python实现数据库并行读取和写入实例的使用技巧和注意事项,需要的朋友参考一下 这篇主要记录一下如何实现对数据库的并行运算来节省代码运行时间。语言是Python,其他语言思路一样。 前言 一共23w条数据,是之前通过自然语言分析处理过的数据,附一张截图: 要实现对news主体的读取,并且找到其中含有的股票名称,只要发现,就将这支股票和
-
本文向大家介绍python读取并定位excel数据坐标系详解,包括了python读取并定位excel数据坐标系详解的使用技巧和注意事项,需要的朋友参考一下 测试数据:坐标数据:testExcelData.xlsx 使用python读取excel文件需要安装xlrd库: xlrd下载后的压缩文件:xlrd-1.2.0.tar.gz 解压后再进行安装即可,具体安装方法请另行百度。 代码 运行结果: 以
-
本文向大家介绍详解java并发之重入锁-ReentrantLock,包括了详解java并发之重入锁-ReentrantLock的使用技巧和注意事项,需要的朋友参考一下 前言 目前主流的锁有两种,一种是synchronized,另一种就是ReentrantLock,JDK优化到现在目前为止synchronized的性能已经和重入锁不分伯仲了,但是重入锁的功能和灵活性要比这个关键字多的多,所以重入锁是
-
本文向大家介绍d3.js入门教程之数据绑定详解,包括了d3.js入门教程之数据绑定详解的使用技巧和注意事项,需要的朋友参考一下 前言 d3.js 是一款上手容易的js类库,专门用于绘制svg图形图表,其关键理念为data-join 意即数据绑定.搞清这个概念非常重要,它将以简洁优雅的形式体现数据驱动编程. 以下是Thinking with Joins的拙译 ,原作者Mike Bostock 假设你