
Mysql中SQL语句不使用索引的情况

MySQL查询不使用索引汇总
众所周知,增加索引是提高查询速度的有效途径,但是很多时候,即使增加了索引,查询仍然不使用索引,这种情况严重影响性能,这里就简单总结几条MySQL不使用索引的情况
如果MySQL估计使用索引比全表扫描更慢,则不使用索引。例如,如果列key均匀分布在1和100之间,下面的查询使用索引就不是很好:select * from table_name where key>1 and key<90;
如果使用MEMORY/HEAP表,并且where条件中不使用“=”进行索引列,那么不会用到索引,head表只有在“=”的条件下才会使用索引
用or分隔开的条件,如果or前的条件中的列有索引,而后面的列没有索引,那么涉及到的索引都不会被用到,例如:select * from table_name where key1='a' or key2='b';如果在key1上有索引而在key2上没有索引,则该查询也不会走索引
复合索引,如果索引列不是复合索引的第一部分,则不使用索引(即不符合最左前缀),例如,复合索引为(key1,key2),则查询select * from table_name where key2='b';将不会使用索引
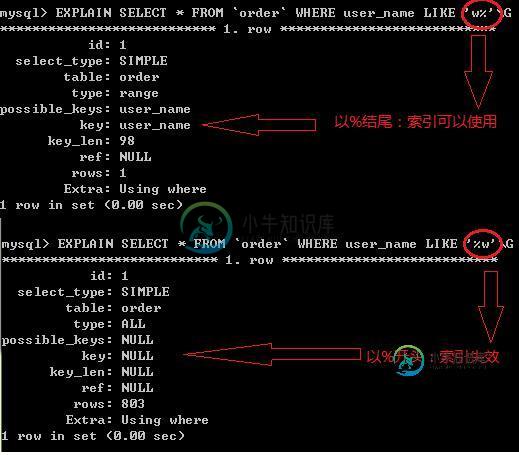
如果like是以‘%'开始的,则该列上的索引不会被使用。例如select * from table_name where key1 like '%a';该查询即使key1上存在索引,也不会被使用
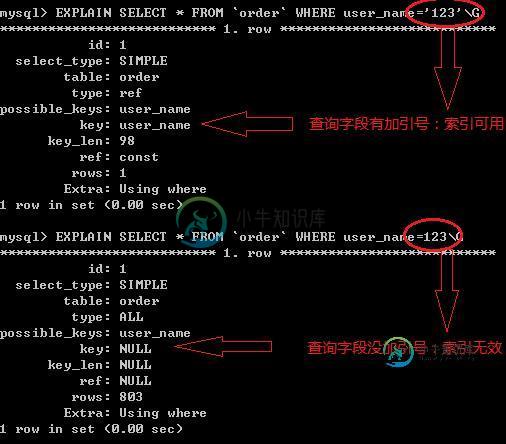
如果列为字符串,则where条件中必须将字符常量值加引号,否则即使该列上存在索引,也不会被使用。例如,select * from table_name where key1=1;如果key1列保存的是字符串,即使key1上有索引,也不会被使用。
从上面可以看出,即使我们建立了索引,也不一定会被使用,那么我们如何知道我们索引的使用情况呢??在MySQL中,有Handler_read_key和Handler_read_rnd_key两个变量,如果Handler_read_key值很高而Handler_read_rnd_key的值很低,则表明索引经常不被使用,应该重新考虑建立索引。可以通过:show status like 'Handler_read%'来查看着连个参数的值。
关于如何正确创建Mysql的索引,请参考怎样正确创建MySQL索引的方法详解;众所周知,数据表索引可以提高数据的检索效率,也可以降低数据库的IO成本,并且索引还可以降低数据库的排序成本;但索引并不是时时都会生效的,比如以下几种情况,将导致索引失效:
1.如果条件中有or,即使其中有条件带索引也不会使用索引(这也是为什么SQL语句中尽量少用or的原因)
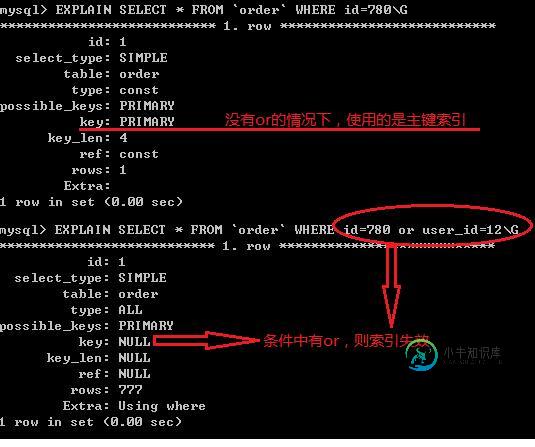
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引。
2.对于多列索引,不是使用的第一部分,则不会使用索引。
3.like查询是以%开头时不会使用索引。
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引。
5.如果 mysql 估计使用全表扫描要比使用索引快,则不使用索引。
此外,查看索引的使用情况
show status like 'Handler_read%';
大家可以注意:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询越低效。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对小牛知识库的支持。如果你想了解更多相关内容请查看下面相关链接
-
我使用的是PostgreSQL v9。6.6. 我正在运行以下SQL: 这将导致以下错误,因为列的索引不是唯一的。我不能添加索引,因为有一些存量数据不是唯一的。 错误:不存在与冲突规范匹配的唯一或排除约束 问:有没有办法在没有索引的情况下执行upsert语句? 谢谢
-
问题内容: 我有以下内容: 创建DB并使用他的前两个 方法工作正常。当运行到该行时,它将引发异常- 问题答案: 这应该在您的情况下有效: 原因:每次执行方法调用时,语句只能执行一个SQL语句。 如果要同时执行两个或多个语句,则可以使用Batch-Jobs来执行。 喜欢:
-
问题内容: 可以说在employee表中,我在表的列上创建了一个索引(idx_name)。 我是否需要在select子句中明确指定索引名称,否则它将自动用于加速查询。 如果需要在select子句中指定,在select查询中使用index的语法是什么? 问题答案: 如果要测试索引以查看其是否有效,请使用以下语法: WITH语句将强制使用索引。
-
主要内容:一、索引概述,1.索引的分类,二、索引的创建,1.创建表时创建索引,2. 在已经存在的表上创建索引,三、删除索引,四、隐藏索引,五、哪些情况下适合创建索引,1.频繁作为 WHERE 查询条件的字段,2. 有唯一性限制的字段,3.经常GROUP BY和ORDER BY的列,4.UPDATE、DELETE的WHERE条件列,,5.DISTINCT字段需要创建索引,6.多表JOIN连接操作时,7. 使用列的类型小的创建索引,,,,,,,,,,,,上一篇我们主要是对索引设计体系的一个讲解,本篇
-
iam在一个非常简单的表上解决一些性能问题,当使用其主键(bigint)获取数据时,这个表似乎很慢 我有这个包含 1.24 亿个条目的表: 以及一个简单的查询,它使用IN子句从另一个表中获取一些id,以从节点表中获取数据,但从这个表中获取几行只需要1小时。EXPLAIN向我展示了它不使用PRIMARY键作为索引,它只是扫描整个表。为什么?另一个表中的id和id列都来自bigint(20)类型。 查
-
问题内容: 我有以下内容: 创建DB并使用他的前两个 方法工作正常。当到达行中时,它将引发异常- 问题答案: 这应该在您的情况下有效: 原因:每次调用execute方法时,语句只能执行一个SQL语句。 如果要同时执行两个或多个语句,则可以使用Batch-Jobs来执行。 喜欢: