
对比分析MySQL语句中的IN 和Exists

背景介绍
最近在写SQL语句时,对选择IN 还是Exists 犹豫不决,于是把两种方法的SQL都写出来对比一下执行效率,发现IN的查询效率比Exists高了很多,于是想当然的认为IN的效率比Exists好,但本着寻根究底的原则,我想知道这个结论是否适用所有场景,以及为什么会出现这个结果。
网上查了一下相关资料,大体可以归纳为:外部表小,内部表大时,适用Exists;外部表大,内部表小时,适用IN。那我就困惑了,因为我的SQL语句里面,外表只有1W级别的数据,内表有30W级别的数据,按网上的说法应该是Exists的效率会比IN高的,但我的结果刚好相反!!
“没有调查就没有发言权”!于是我开始研究IN 和Exists的实际执行过程,从实践的角度出发,在根本上去寻找原因,于是有了这篇博文分享。
实验数据
我的实验数据包括两张表:t_author表 和 t_poetry表。
对应表的数据量:
t_author表,13355条记录;
t_poetry表,289917条记录。
对应的表结构如下:
CREATE TABLE t_poetry (
id bigint(20) NOT NULL AUTO_INCREMENT,
poetry_id bigint(20) NOT NULL COMMENT '诗词id',
poetry_name varchar(200) NOT NULL COMMENT '诗词名称',
<font color=red> author_id bigint(20) NOT NULL COMMENT '作者id'</font>
PRIMARY KEY (id),
UNIQUE KEY pid_idx (poetry_id) USING BTREE,
KEY aid_idx (author_id) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=291270 DEFAULT CHARSET=utf8mb4
CREATE TABLE t_author (
id int(15) NOT NULL AUTO_INCREMENT,
author_id bigint(20) NOT NULL,</font>
author_name varchar(32) NOT NULL,
dynasty varchar(16) NOT NULL,
poetry_num int(8) NOT NULL DEFAULT '0'
PRIMARY KEY (id),
<font color=red>UNIQUE KEY authorid_idx (author_id) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=13339 DEFAULT CHARSET=utf8mb4
执行计划分析 IN 执行过程
sql示例:select * from tabA where tabA.x in (select x from tabB where y>0 );
其执行计划:
(1)执行tabB表的子查询,得到结果集B,可以使用到tabB表的索引y;
(2)执行tabA表的查询,查询条件是tabA.x在结果集B里面,可以使用到tabA表的索引x。
Exists执行过程
sql示例:select from tabA where exists (select from tabB where y>0);
其执行计划:
(1)先将tabA表所有记录取到。
(2)逐行针对tabA表的记录,去关联tabB表,判断tabB表的子查询是否有返回数据,5.5之后的版本使用Block Nested Loop(Block 嵌套循环)。
(3)如果子查询有返回数据,则将tabA当前记录返回到结果集。
tabA相当于取全表数据遍历,tabB可以使用到索引。
实验过程
实验针对相同结果集的IN和Exists 的SQL语句进行分析。
包含IN的SQL语句:
select from t_author ta where author_id in
(select author_id from t_poetry tp where tp.poetry_id>3650 );
包含Exists的SQL语句:
select from t_author ta where exists
(select * from t_poetry tp where tp.poetry_id>3650 and tp.author_id=ta.author_id);
第一次实验数据情况
t_author表,13355条记录;t_poetry表,子查询筛选结果集 where poetry_id>293650 ,121条记录;
执行结果
使用exists耗时0.94S, 使用in耗时0.03S,IN 效率高于Exists
原因分析
对t_poetry表的子查询结果集很小,且两者在t_poetry表都能使用索引,对t_poetry子查询的消耗基本一致。两者区别在于,使用 in 时,t_author表能使用索引:
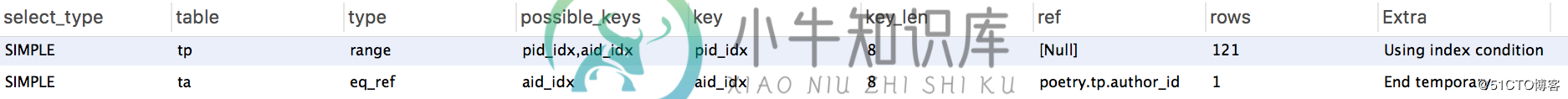
使用exists时,t_author表全表扫描:

在子查询结果集较小时,查询耗时主要表现在对t_author表的遍历上。
第二次实验数据情况
t_author表,13355条记录;t_poetry表,子查询筛选结果集 where poetry_id>3650 ,287838条记录;
执行时间
使用exists耗时0.12S, 使用in耗时0.48S,Exists效率高于 IN。
原因分析
两者的索引使用情况跟第一次实验是一致的,唯一区别是子查询筛选结果集的大小不同,但实验结果已经跟第一次的不同了。这种情况下子查询结果集很大,我们看看mysql的查询计划:
使用in时,由于子查询结果集很大,对t_author和t_poetry表都接近于全表扫描,此时对t_author表的遍历耗时差异对整体效率影响可以忽略,执行计划里多了一行<auto_key>,在接近全表扫描的情况下,mysql优化器选择了auto_key来遍历t_author表:

使用exists时,数据量的变化没有带来执行计划的改变,但由于子查询结果集很大,5.5以后的MySQL版本在exists匹配查询结果时使用的是Block Nested-Loop(Block嵌套循环,引入join buffer,类似于缓存功能)开始对查询效率产生显著影响,尤其针对<font color=red>子查询结果集很大</font>的情况下能显著改善查询匹配效率:

实验结论
根据上述两个实验及实验结果,我们可以较清晰的理解IN 和Exists的执行过程,并归纳出IN 和Exists的适用场景:
IN查询在内部表和外部表上都可以使用到索引; Exists查询仅在内部表上可以使用到索引;当子查询结果集很大,而外部表较小的时候,Exists的Block Nested Loop(Block 嵌套循环)的作用开始显现,并弥补外部表无法用到索引的缺陷,查询效率会优于IN。当子查询结果集较小,而外部表很大的时候,Exists的Block嵌套循环优化效果不明显,IN 的外表索引优势占主要作用,此时IN的查询效率会优于Exists。 网上的说法不准确。其实“表的规模”不是看内部表和外部表,而是外部表和子查询结果集。最后一点,也是最重要的一点:世间没有绝对的真理,掌握事物的本质,针对不同的场景进行实践验证才是最可靠有效的方法。 实验过程中发现的问题补充
仅对不同数据集情况下的上述exists语句分析时发现,数据集越大,消耗的时间反而变小,觉得很奇怪。
具体查询条件为:
where tp.poetry_id>3650,耗时0.13S
where tp.poetry_id>293650,耗时0.46S
可能原因:条件值大,查询越靠后,需要遍历的记录越多,造成最终消耗越多的时间。这个解释有待进一步验证后再补充。
-
本文向大家介绍python中in在list和dict中查找效率的对比分析,包括了python中in在list和dict中查找效率的对比分析的使用技巧和注意事项,需要的朋友参考一下 首先给一个简单的例子,测测list和dict查找的时间: 运行结果: 通过上例我们可以看到list的查找效率远远低于dict的效率,原因如下: python中list对象的存储结构采用的是线性表,因此其查询复杂度为O(n
-
本文向大家介绍浅谈MySQL和Lucene索引的对比分析,包括了浅谈MySQL和Lucene索引的对比分析的使用技巧和注意事项,需要的朋友参考一下 MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr、ElasticSearch)的核心类库。两者的索引(index)有什么区别呢?以前写过一篇《Solr与MySQL查询性能对比》,只是简单的
-
本文向大家介绍MySQL语句加锁的实现分析,包括了MySQL语句加锁的实现分析的使用技巧和注意事项,需要的朋友参考一下 摘要: MySQL两条SQL语句锁的分析 看一下下面的SQL语句加什么锁 (1)id 是不是主键 (2)当前系统的隔离级别是什么 (3)id列如果不是主键,那么id列上有索引吗 (4)id列上如果有二级索引,那么这个索引是二级索引吗 (5)两个SQL的执行计划是什么?索引扫描还是
-
问题内容: 我的一个表中有一列,其中存储多个用逗号分隔的ID。有没有一种方法可以在查询的“ IN”子句中使用此列的值。 column()的值类似于 我需要用作 我对Crozin的回答感到满意,但我愿意接受建议,观点和选择。 随时分享您的观点。 问题答案: 以@Jeremy Smith的FIND_IN_SET()示例为基础,您可以使用联接来完成此操作,因此不必运行子查询。 这是众所周知的非常表现
-
本文向大家介绍mysql中EXISTS和IN的使用方法比较,包括了mysql中EXISTS和IN的使用方法比较的使用技巧和注意事项,需要的朋友参考一下 1、使用方式: (1)EXISTS用法 上面这条SQL的意思就是:以ucsc_project_batch为主表查询batchName与projectId字段,其中projectId字段存在于ucsc_project表中。 EXISTS 会对外表uc
-
本文向大家介绍Android getReadableDatabase() 和 getWritableDatabase()分析对比,包括了Android getReadableDatabase() 和 getWritableDatabase()分析对比的使用技巧和注意事项,需要的朋友参考一下 Android getReadableDatabase() 和 getWritableDatabase()分