
泛谈Java NIO

前言
非阻塞IO,也被称之为新IO,它重新定义了一些概念。
1.缓冲buffer
2.通道 channel
3.通道选择器
BIO 阻塞IO,几乎所有的java程序员都会的字节流,字符流,输入流,输出流等分类就是针对BIO而言的。我们在使用BIO的时候都是建立基本的节点流然后用过滤流进行包装。
不同于BIO,NIO所有的IO操作都是通过通道读写buffer完成的。数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
通道
NIO的通道类似流,但是有所不同。
1.既可以从通道中读取数据,又可以写数据到通道。而流的读写通常是单向的
2.通道就是类似与高速路,数据通过buffer传递。通道负责从buffer中读,或者写入buffer
3.通道可以异步读写
- FileChannel 从文件中读写数据
- DatagramChannel 能通过UDP读写网络中的数据
- SocketChannel 能通过TCP读写网络中的数据
- ServerSocketChannel可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel
Buffer
Buffer 用来缓存数据,NIO中所有的操作都是基于缓冲区继续操作的,所有的读写操作都是通过缓存区来进行完成。缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
缓冲区基本属性
- 容量 (capacity):表示 Buffer 最大数据容量,缓冲区容量不能为负,并且创建后不能更改。
- 限制 (limit)
- 位置 (position)
position和limit的含义取决于Buffer处在读模式还是写模式。不管Buffer处在什么模式,capacity都代表容量。
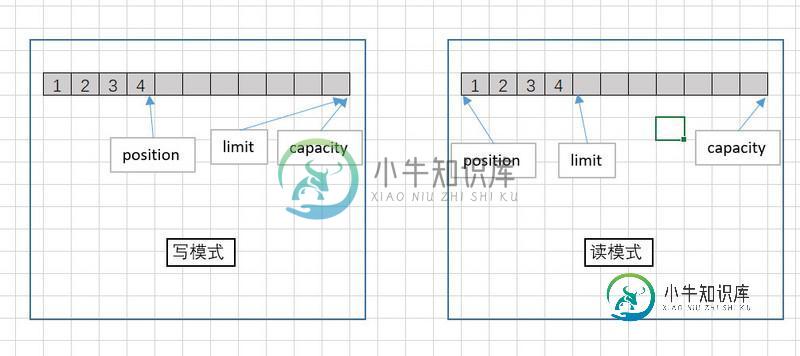
Buffer有一个固定的大小值,叫“capacity”。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。
写模式
当你写数据到Buffer中时,position表示当前的位置。初始的position值为0,当一个byte、long等数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity – 1。在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。
读模式
当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0。当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值等于在写模式下position)。
使用
使用Buffer读写数据一般遵循以下四个步骤:
1.写入数据到Buffer
2.调用flip()方法
3.从Buffer中读取数据
4.调用clear()方法或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据。一旦要读取数据,需要通过flip()方法将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
使用案例如下:
import java.io.FileInputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
public class TestNio {
public static void main(String[] args) throws Exception {
/*FileOutputStream outputStream = new FileOutputStream("E:/i.txt");
FileChannel channel = outputStream.getChannel();
ByteBuffer buffer = ByteBuffer.wrap("hahahah".getBytes());
channel.write(buffer);
channel.close();*/
FileInputStream inputStream = new FileInputStream("E:/i.txt");
FileChannel channel = inputStream.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true){
// 读数据写入buffer 如果读了6个数据 那么positon limit均为6
int read = channel.read(buffer);
if(read == -1) break;
// 把position设置为0 写操作变为读操作(相对与buffer而言)
buffer.flip();
// hasRemaining当 position和limit相等的时候为false
while (buffer.hasRemaining()){
byte b = buffer.get();
System.out.println((char)b);
}
// clear实际上是positon 和 limit均置为0 数据实际上是未清楚的
// 读操作变为写操作(相对与buffer)
buffer.clear();
}
channel.close();
ByteBuffer wrap = new ByteBuffer.wrap("哈哈哈".getBytes());
// 编码处理
Charset gbk = Charset.forName("GBK");
ByteBuffer encode = gbk.encode("哈哈哈");
}
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
在Java中,大家都知道整数不能转换为字符串,这是编译时的一个错误。 对于这个一般的情况, 我只是不明白为什么在这种情况下,java不能在编译时警告您整数转换为字符串。为什么?据我所知,类型删除是在编译后发生的。 编辑:我只是以为编译器有类型推断才知道T是字符串,这样就不能将Integer强制转换为。但显然没有。
-
本文向大家介绍浅谈java中定义泛型类和定义泛型方法的写法,包括了浅谈java中定义泛型类和定义泛型方法的写法的使用技巧和注意事项,需要的朋友参考一下 1、方法中的泛型 2、定义泛型类 以上这篇浅谈java中定义泛型类和定义泛型方法的写法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
本文向大家介绍详谈Java8新特性泛型的类型推导,包括了详谈Java8新特性泛型的类型推导的使用技巧和注意事项,需要的朋友参考一下 1. 泛型究竟是什么? 在讨论类型推导(type inference)之前,必须回顾一下什么是泛型(Generic).泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。通俗点将就是“类型的变量”。这种类型变量可
-
本文向大家介绍浅谈java泛型的作用及其基本概念,包括了浅谈java泛型的作用及其基本概念的使用技巧和注意事项,需要的朋友参考一下 一、泛型的基本概念 java与c#一样,都存在泛型的概念,及类型的参数化。java中的泛型是在jdk5.0后出现的,但是java中的泛型与C#中的泛型是有本质区别的,首先从集合类型上来说,java 中的ArrayList<Integer>和ArrayList<Stri
-
本文向大家介绍浅谈Java泛型通配符解决了泛型的许多诟病(如不能重载),包括了浅谈Java泛型通配符解决了泛型的许多诟病(如不能重载)的使用技巧和注意事项,需要的朋友参考一下 泛型: 泛型的方法不能重载,因为泛型擦出后是一样的方法,也就是如果一个方法里的形参的泛型的,则不能重载这个方法,即:即使方法名相同,参数不同也不行,但是普通方法可以重载(同名不同参) 那个HTML本来打算过渡到XML的,且中
-
问题内容: 我有一个代表文本片段的泛型类。该文本片段可能具有多种不同模式(突出显示的不同类型)中的任何一种。这些模式用枚举表示。每个项目的Enum可能不同,但是它必须实现一个接口,该接口提供了一种将其中两个结合的方法(可以突出显示并加粗显示)。所以我有一个界面: 然后我的TextFragment是文本字符串和模式的容器。但是当我尝试声明该类时: 我收到以下错误: 令牌“扩展”的语法错误,预期 根据
-
理论之后,我们转移到一些实际功能上面,这会让我们更加简单地掌握它。为了不重复发明轮子,我使用三个Kotlin标准库中的三个函数。这些函数让我们仅使用泛型的实现就可以做一些很棒的事情。它可以鼓舞你创建自己的函数。 let let实在是一个简单的函数,它可以被任何对象调用。它接收一个函数(接收一个对象,返回函数结果)作为参数,作为参数的函数返回的结果作为整个函数的返回值。它在处理可null对象的时候是
-
本文向大家介绍谈谈对html5的了解相关面试题,主要包含被问及谈谈对html5的了解时的应答技巧和注意事项,需要的朋友参考一下 1.良好的移动性,以移动设备为主。 2.响应式设计,以适应自动变化的屏幕尺寸 3.支持离线缓存技术,webStorage本地缓存 4.新增canvas,video,audio等新标签元素。新增特殊内容元素:article,footer,header,nav,section