
SQL Server两种分页的存储过程使用介绍

由于现在很多的企业招聘的笔试都会让来招聘的写一个分页的存储过程,有的企业甚至要求应聘者用两种方式实现分页,如果没有在实际项目中使用过分页,那么很多的应聘者都会出现一定的问题,下面介绍两种分页的方法。
一、 以学生表为例,在数据库中有一个Student表,字段有StudentNo, ,LoginPwd, StudentName,Sex,ClassId,Phone,Address,BornDate,Email,isDel
要求:查询学生的信息,每页显示5条记录
二、第一种方式分页:利用子查询 not in
例如:
第一页
select top 5 * from Student
第二页: 查询前10条中不在前5条的记录,那么就是6-10,也就是第二页
select top 5 * from Student where StudentNo not in(select top 10 Studentno from Student)
同理可以得到第三页、、、、、、、
这种方式相信大家都能明白,这种分页的存储过程写法就不多做介绍,重点介绍下面那种分页方法。
三、第二种方式分页:利用ROW_NUMBER()这个自带的函数
因为自05之后,提供一个专门用于分页的函数,那就是ROW_NUMBER()这个函数,分页的基本语法:ROW_NUMBER() over(排序字段):可以根据指定的字段排序,对排序之后的结果集的每一行添加一个不间断的行号,相当于连续的id值一样,
例如sql语句:select ROW_NUMBER() over(order by studentno) id, * from Student 那么结果集可以看到:
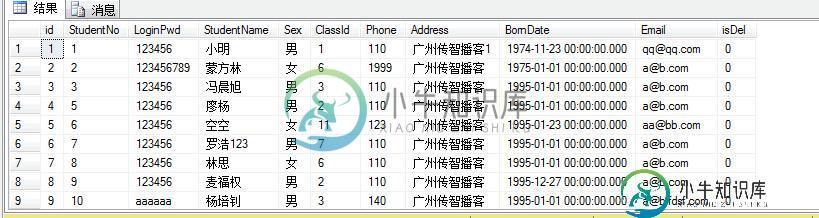
那么我们可以看到id值是连续的,所有接下来的存储过程写起来就比较简单了。
注意:我们必须为这个结果集命一个新名字,比如我们命名为temp,那么分页存储过程可以写出:
if exists( select * from sysobjects where name='usp_getPageData') drop proc usp_getPageData --如果存在名字为usp_getPageData的存储过程则删除 go create proc usp_getPageData --创建名字usp_getPageData存储过程 @toPage int=0 output, --总页数 @pageIndex int =1 , --默认显示第一页 @pageCount int =5 --默认每页的记录为5条 as select temp.StudentNo,temp.LoginPwd,temp.StudentName,temp.Sex,temp.ClassId,temp.Phone,temp.Address,temp.BornDate,temp.Email,temp.isDel from (select ROW_NUMBER() over (Order by studentno) id,* from Student) temp where id>(@pageIndex-1)*@pageCount and id<=@pageIndex*@pageCount set @toPage=ceiling((select COUNT(*) from Student)*1.0/@pageCount) --使用ceiling函数算出总页数 go
说明因为在实际的项目的开发中,经常要显示总页数给用户看的,所有这里的存储过程增加了一个toPage参数,由于它是要输出给用户看的,所有参数类型定义为output,并用set进行赋值。
以上是对两种分页方法的介绍,如果有任何疑问或不懂的可以留言给我。
-
本文向大家介绍SqlServer 2000、2005分页存储过程整理第1/3页,包括了SqlServer 2000、2005分页存储过程整理第1/3页的使用技巧和注意事项,需要的朋友参考一下 sql server 2005的分页存储过程分3个版本,一个是没有优化过的,一个是优化过的,最后一个支持join的,sql server 2000的分页存储过程,也可以运行在sql server 2005上,
-
问题内容: 我正在尝试添加分页存储过程的排序功能。 我该怎么做,到目前为止,我已经创建了这个。它工作正常,但是当传递参数时,它不起作用。 问题答案: 一种方法(可能不是最好的方法)是使用动态SQL 这是 SQLFiddle 演示
-
问题内容: 我有一张桌子,我需要在99%的时间内自动分配ID(其他1%似乎使用身份列来排除)。因此,我有一个存储过程来获取以下行中的下一个ID: `` 检查必须检查用户是否手动使用了ID并找到下一个未使用的ID。 当我依次调用它并返回1、2、3时,它可以正常工作。我需要做的是在多个进程同时调用此方法的情况下提供一些锁定。理想情况下,我只需要它专用于围绕此代码锁定last_auto_id表,以便第二
-
本文向大家介绍sqlserver中存储过程的递归调用示例,包括了sqlserver中存储过程的递归调用示例的使用技巧和注意事项,需要的朋友参考一下 递归式指代码片段调用自身的情况;危险之处在于:如果调用了自身一次,那么如何防止他反复地调用自身。也就是说提供递归检验来保证适当的时候可以跳出。 以阶层为例子说存储过程中递归的调用。 递归 当创建此存储过程时候,会遇见一条报告信息
-
本文向大家介绍查询Sqlserver数据库死锁的一个存储过程分享,包括了查询Sqlserver数据库死锁的一个存储过程分享的使用技巧和注意事项,需要的朋友参考一下 使用sqlserver作为数据库的应用系统,都避免不了有时候会产生死锁, 死锁出现以后,维护人员或者开发人员大多只会通过sp_who来查找死锁的进程,然后用sp_kill杀掉。利用sp_who_lock这个存储过程,可以很方便的知道哪个
-
本文向大家介绍SQL Server 分页查询通用存储过程(只做分页查询用),包括了SQL Server 分页查询通用存储过程(只做分页查询用)的使用技巧和注意事项,需要的朋友参考一下 自开始做项目以来,一直在用。这段存储过程的的原创者(SORRY,忘记名字了),写得这段SQL代码很不错,我在这个基础上,按照我的习惯以及思维方式,调整了代码,只做分页查询用。 调用方法: prcPageResult
-
本文向大家介绍oracle中存储函数与存储过程的区别介绍,包括了oracle中存储函数与存储过程的区别介绍的使用技巧和注意事项,需要的朋友参考一下 在oracle中,函数和存储过程是经常使用到的,他们的语法中有很多相似的地方,可是也有它们的不同之处,这段时间刚学完函数与存储过程,来给自己做一个总结: 一:存储过程:简单来说就是有名字的pl/sql块。 语法结构: 案例:
-
问题内容: 我试图在postgres 9.3上使用sql调用函数内的函数。 这个问题与我的另一篇文章有关。 我写了下面的函数。到目前为止,我还没有合并任何类型的save-output(COPY)语句,因此我试图通过创建嵌套函数print-out函数来解决此问题。 以上功能有效。 尝试创建嵌套函数。 调用嵌套函数。 输出 上面给出了这个。但是,当在print_out()中将arg1,arg2替换为’