
Python实现将xml导入至excel

最近在使用Testlink时,发现导入的用例是xml格式,且没有合适的工具转成excel格式,xml使用excel打开显示的东西也太多,网上也有相关工具转成csv格式的,结果也不合人意。
那求人不如尔己,自己写一个吧
需要用到的模块有:xml.dom.minidom(python自带)、xlwt
使用版本:
python:2.7.5
xlwt:1.0.0
一、先分析Testlink XML格式:
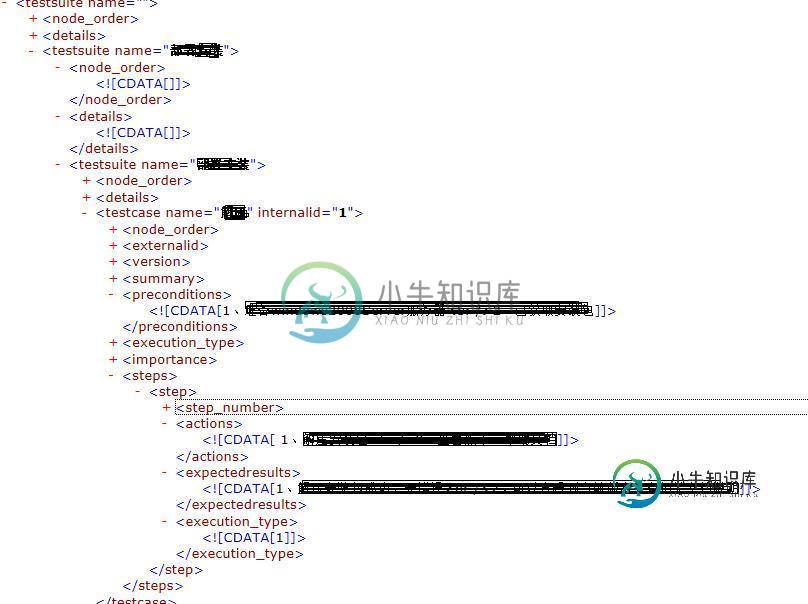
这是一个有两级testusuit的典型的testlink用例结构,我们只需要取testsuite name,testcase name,preconditions,actions,expectedresults
二、程序如下:
#coding:utf-8 ''' Created on 2015-8-20 @author: Administrator ''' ''' ''' import xml.etree.cElementTree as ET import xml.dom.minidom as xx import os,xlwt,datetime workbook=xlwt.Workbook(encoding="utf-8") # booksheet=workbook.add_sheet(u'sheet_1') booksheet.col(0).width= 5120 booksheet.col(1).width= 5120 booksheet.col(2).width= 5120 booksheet.col(3).width= 5120 booksheet.col(4).width= 5120 booksheet.col(5).width= 5120 dom=xx.parse(r'D:\\Python27\test.xml') root = dom.documentElement row=1 col=1 borders=xlwt.Borders() borders.left=1 borders.right=1 borders.top=1 borders.bottom=1 style = xlwt.easyxf('align: wrap on,vert centre, horiz center') #自动换行、水平居中、垂直居中 #设置标题的格式,字体方宋、加粗、背景色:菊黄 #测试项的标题 title=xlwt.easyxf(u'font:name 仿宋,height 240 ,colour_index black, bold on, italic off; align: wrap on, vert centre, horiz center;pattern: pattern solid, fore_colour light_orange;') item='测试项' Subitem='测试分项' CaseTitle="测试用例标题" Condition='预置条件' actions='操作步骤' Result='预期结果' booksheet.write(0,0,item,title) booksheet.write(0,1,Subitem,title) booksheet.write(0,2,CaseTitle,title) booksheet.write(0,3,Condition,title) booksheet.write(0,4,actions,title) booksheet.write(0,5,Result,title) #冻结首行 booksheet.panes_frozen=True booksheet.horz_split_pos= 1 #一级目录 for i in root.childNodes: testsuite=i.getAttribute('name').strip() #print testsuite #print testsuite ''' 写测试项 ''' print "row is :",row booksheet.write(row,col,testsuite,style) #二级目录 for dd in i.childNodes: print " %s" % dd.getAttribute('name') testsuite2=dd.getAttribute('name') if not dd.getElementsByTagName('testcase'): print "Testcase is %s" % testsuite2 row=row+1 booksheet.write(row,2,testsuite2,style) #写测试分项 row=row+1 booksheet.write(row,1,testsuite2,style) itemlist=dd.getElementsByTagName('testcase') for subb in itemlist: #print " %s" % subb.getAttribute('name') testcase=subb.getAttribute('name') row=row+1 booksheet.write(row,2,testcase,style) ilist=subb.getElementsByTagName('preconditions') for ii in ilist: preconditions=ii.firstChild.data.replace("<br />"," ") col=col+1 booksheet.write(row,3,preconditions,style) steplist=subb.getElementsByTagName('actions') #print steplist for step in steplist: actions=step.firstChild.data.replace("<br />"," ") col=col+1 booksheet.write(row,4,actions,style) #print "测试步骤:",steplist[0].firstChild.data.replace("<br />"," ") expectlist=subb.getElementsByTagName('expectedresults') for expect in expectlist: result=expect.childNodes[0].nodeValue.replace("<br />","" ) booksheet.write(row,5,result,style) row=row+1 workbook.save('demo.xls')
写入excel的效果如下:

我们再来看个实例:
需要下载一个module:xlwt,如下是source code
import xml.dom.minidom
import xlwt
import sys
col = 0
row = 0
def handle_xml_report(xml_report, excel):
problems = xml_report.getElementsByTagName("problem")
handle_problems(problems, excel)
def handle_problems(problems, excel):
for problem in problems:
handle_problem(problem, excel)
def handle_problem(problem, excel):
global row
global col
code = problem.getElementsByTagName("code")
file = problem.getElementsByTagName("file")
line = problem.getElementsByTagName("line")
message = problem.getElementsByTagName("message")
for node in code:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in file:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in line:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in message:
excel.write(row, col, node.firstChild.data)
col = col + 1
row = row+1
col = 0
if __name__ == '__main__':
if(len(sys.argv) <= 1):
print ("usage: xml2xls src_file [dst_file]")
exit(0)
#the 1st argument is XML report ; the 2nd is XLS report
if(len(sys.argv) == 2):
xls_report = sys.argv[1][:-3] + 'xls'
#if there are more than 2 arguments, only the 1st & 2nd make sense
else:
xls_report = sys.argv[2]
xmldoc = xml.dom.minidom.parse(sys.argv[1])
wb = xlwt.Workbook()
ws = wb.add_sheet('MOLint')
ws.write(row, col, 'Error Code')
col = col + 1
ws.write(row, col, 'file')
col = col + 1
ws.write(row, col, 'line')
col = col + 1
ws.write(row, col, 'Description')
row = row + 1
col = 0
handle_xml_report(xmldoc, ws)
wb.save(xls_report)
-
本文向大家介绍在Python中实现导入(importlib),包括了在Python中实现导入(importlib)的使用技巧和注意事项,需要的朋友参考一下 importlib软件包提供了可移植到任何Python解释器的Python源代码中import语句的实现。这也提供了比用Python以外的其他编程语言实现的实现更容易理解的实现。 该软件包还公开了实现导入的组件,使用户可以更轻松地创建自己的自定
-
问题内容: 我知道寻求这种帮助并不是一件容易的事,但是我已经坚持了一段时间-现在我正在阅读两本C#书,每天工作超过9个小时。 好的,这是我的问题:我有一个几乎完整的WinForms C#应用程序。在SQL中,我有三个看起来像这样的表: 我在本地磁盘上有XML文件,用于导入这三个表-XML看起来像这样: 再一次让我感到尴尬,以这种方式请求帮助,但是我将尽一切可能尝试支持StackOverflow。
-
问题内容: 我在Microsoft.com上查看了以下示例: http://support.microsoft.com/kb/316005 http://msdn.microsoft.com/zh- CN/library/aa225754%28v=sql.80%29.aspx 但这是在其中一部分步骤中必须执行VBScript代码,而我无法找到应该在何处执行VBScript。是否可以在SQL Ser
-
问题内容: 我应该使用 要么 当 导入模块 ,并和有 改变名字没有必要/愿望 ()? 有什么区别吗?有关系吗? 问题答案: 假设是中的模块或包,没有区别*,那就没关系。这两个语句具有完全相同的结果: 如果不是模块或软件包,则第二种形式将不起作用;引发回溯: *在Python 3.6及更高版本中,包含其他模块的软件包的初始化顺序存在一个错误,即在软件包 的加载阶段,在子模块中使用 该软件包 会失败,
-
我已经安装了Sonarqube5.1.2和Checkstyle插件2.3。 我已经尝试导出一个现有的预装规则集,并尝试用其他名称导入它。但这会导致同样的失败。 这也是一个bug吗?
-
本文向大家介绍java实现Excel的导入、导出,包括了java实现Excel的导入、导出的使用技巧和注意事项,需要的朋友参考一下 一、Excel的导入 导入可采用两种方式,一种是JXL,另一种是POI,但前者不能读取高版本的Excel(07以上),后者更具兼容性。由于对两种方式都进行了尝试,就都贴出来分享(若有错误,请给予指正) 方式一、JXL导入 所需jar包 JXL.jar 方式二、POI