
如何实现更换Jupyter Notebook内核Python版本

我使用anaconda安装的python3.6.3,并且自己建立一个虚拟环境,虚拟环境下的python版本也是3.6.3,Jupyter Notebook的内核P丫头好哦哦呢指向的是虚拟环境下的python,最近在使用matplotlib库的遇到了下面的问题:
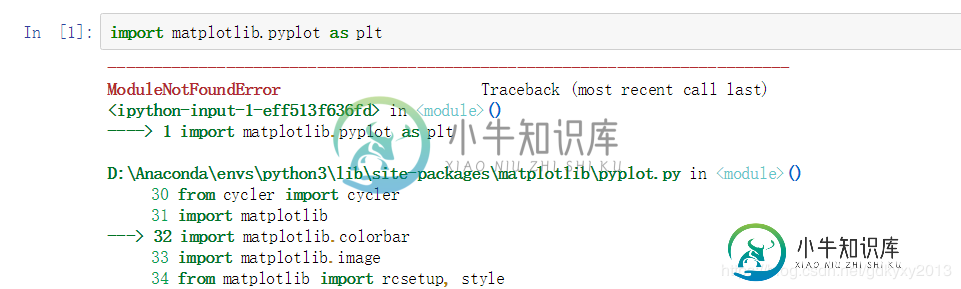
我的lib目录下是有matplotlib以及相关的库的,重装什么的都试过,无奈实在是找不到解决的办法,于是想更换一下Jupyter Notebook的内核Python版本。接下来具体看一下如何更换内核Python版本。
1、首先在cmd下进入python执行如下命令:
import sys sys.executable
可以得到如下的结果:

同时在Jupyter Notebook下执行相同的命令,得到结果如下:

由上面的执行结果可以看到两处指向的位置确实不同。
2、接下来我们需要找到Jupyter Notebook内核指定的Python环境位置,然后改成在cmd下环境指向的位置即可。在cmd下执行如下命令:
ipython kernelspec list
输出的结果中会包含一个位置,如下图所示:

3、接下来,去到虚拟环境python的这个文件夹下,并打开kernel.json这个文件,文件内容如下:
{
"argv": [
"D:\\Anaconda\\envs\\python3\\python.exe",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "Python 3",
"language": "python"
}
可以看到里面定义了Python解释器的位置,更改Python解释器的位置并保存。
4、重启Jupyter Notebook即可。
到此这篇关于如何实现更换Jupyter Notebook内核Python版本的文章就介绍到这了,更多相关Jupyter Notebook内核Python版本内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
我正在使用约克托项目来构建 linux os 映像。我使用SUMO版本,所以我有4.14.73内核版本。 问题是我有预编译的linux驱动,版本是4.14.88。 我认为我必须升级我的linux内核,使其成为相同版本的驱动程序。 知道怎么做吗?
-
问题内容: 所有, 下面的代码来自“ Unix环境中的高级编程”,它创建一个新线程,并打印主线程和新线程的进程ID和线程ID。 在书中,它表示在linux中,此代码的输出将显示两个线程具有不同的进程ID,因为pthread使用轻量级进程来模拟线程。但是,当我在Ubuntu 12.04中运行此代码时,它具有内核3.2,并打印了相同的pid。 那么,新的Linux内核是否会更改pthread的内部实现
-
问题内容: 在多处理器上,每个内核可以有自己的变量。我以为它们是在不同地址中的不同变量,尽管它们在同一过程中并且具有相同的名称。 但是我想知道,内核如何实现呢?它是否分配了一块内存来存放所有的percpu指针,并且每次它通过shift或其他方式将指针重定向到某个地址时? 问题答案: 普通全局变量不是每个CPU的。自动变量位于堆栈中,并且不同的CPU使用不同的堆栈,因此自然会得到单独的变量。 我猜您
-
问题内容: 假设我为使用版本10内核的OS制作了一个映像,如果我在运行版本9内核的主机OS上为该映像运行一个容器,那么Docker会表现出什么行为?那版本11呢? 版本的向后兼容性重要吗?我出于好奇而问,因为文档仅讨论“最低Linux内核版本”等。这听起来像主机运行的内核版本超出该最低值无关紧要。这是真的?有警告吗? 问题答案: 假设我为使用版本10内核的操作系统制作映像。 我认为这是一个误解
-
实现内核重映射 在上文中,我们虽然构造了一个简单映射使得内核能够运行在虚拟空间上,但是这个映射是比较粗糙的。 我们知道一个程序通常含有下面几段: .text 段:存放代码,需要可读、可执行的,但不可写; .rodata 段:存放只读数据,顾名思义,需要可读,但不可写亦不可执行; .data 段:存放经过初始化的数据,需要可读、可写; .bss 段:存放零初始化的数据,需要可读、可写。 我们看到各个
-
问题内容: 我想构建一个将与所有内核发行版兼容的内核模块。例如,如果我在内核3.2.0-29上构建内核模块并尝试在3.2.0-86上加载它,则会出现以下错误: modprobe my_driver 致命:插入my_driver(/lib/modules/3.2.0-86-generic/kernel/fs/my_drv/my_drv.ko)时出错:无效的模块格式 [在日志消息中:my_drv:对符