
Scala中正则表达式以及与模式匹配结合(多种方式)

正则表达式
//"""原生表达 val regex="""([0-9]+)([a-z]+)""".r val numPattern="[0-9]+".r val numberPattern="""\s+[0-9]+\s+""".r
说明:.r()方法简介:Scala中将字符串转换为正则表达式
/** You can follow a string with `.r`, turning it into a `Regex`. E.g. * * `"""A\w*""".r` is the regular expression for identifiers starting with `A`. */ def r: Regex = r()
模式匹配一
//findAllIn()方法返回遍历所有匹配项的迭代器
for(matchString <- numPattern.findAllIn("99345 Scala,22298 Spark"))
println(matchString)
说明:findAllIn(…)函数简介
/** Return all non-overlapping matches of this `Regex` in the given character
* sequence as a [[scala.util.matching.Regex.MatchIterator]],
* which is a special [[scala.collection.Iterator]] that returns the
* matched strings but can also be queried for more data about the last match,
* such as capturing groups and start position.
*
* A `MatchIterator` can also be converted into an iterator
* that returns objects of type [[scala.util.matching.Regex.Match]],
* such as is normally returned by `findAllMatchIn`.
*
* Where potential matches overlap, the first possible match is returned,
* followed by the next match that follows the input consumed by the
* first match:
*
* {{{
* val hat = "hat[^a]+".r
* val hathaway = "hathatthattthatttt"
* val hats = (hat findAllIn hathaway).toList // List(hath, hattth)
* val pos = (hat findAllMatchIn hathaway map (_.start)).toList // List(0, 7)
* }}}
*
* To return overlapping matches, it is possible to formulate a regular expression
* with lookahead (`?=`) that does not consume the overlapping region.
*
* {{{
* val madhatter = "(h)(?=(at[^a]+))".r
* val madhats = (madhatter findAllMatchIn hathaway map {
* case madhatter(x,y) => s"$x$y"
* }).toList // List(hath, hatth, hattth, hatttt)
* }}}
*
* Attempting to retrieve match information before performing the first match
* or after exhausting the iterator results in [[java.lang.IllegalStateException]].
* See [[scala.util.matching.Regex.MatchIterator]] for details.
*
* @param source The text to match against.
* @return A [[scala.util.matching.Regex.MatchIterator]] of matched substrings.
* @example {{{for (words <- """\w+""".r findAllIn "A simple example.") yield words}}}
*/
def findAllIn(source: CharSequence) = new Regex.MatchIterator(source, this, groupNames)

模式匹配二
//找到首个匹配项
println(numberPattern.findFirstIn("99ss java, 222 spark,333 hadoop"))
模式匹配三
//数字和字母的组合正则表达式 val numitemPattern="""([0-9]+) ([a-z]+)""".r val numitemPattern(num, item)="99 hadoop"
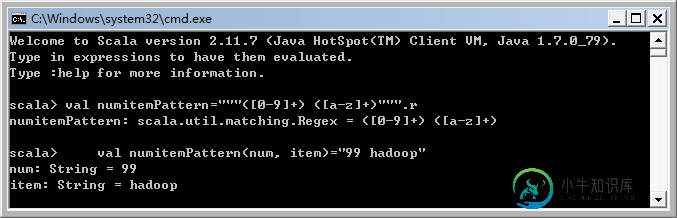
模式匹配四
//数字和字母的组合正则表达式
val numitemPattern="""([0-9]+) ([a-z]+)""".r
val line="93459 spark"
line match{
case numitemPattern(num,blog)=> println(num+"\t"+blog)
case _=>println("hahaha...")
}

val line="93459h spark"
line match{
case numitemPattern(num,blog)=> println(num+"\t"+blog)
case _=>println("hahaha...")
}

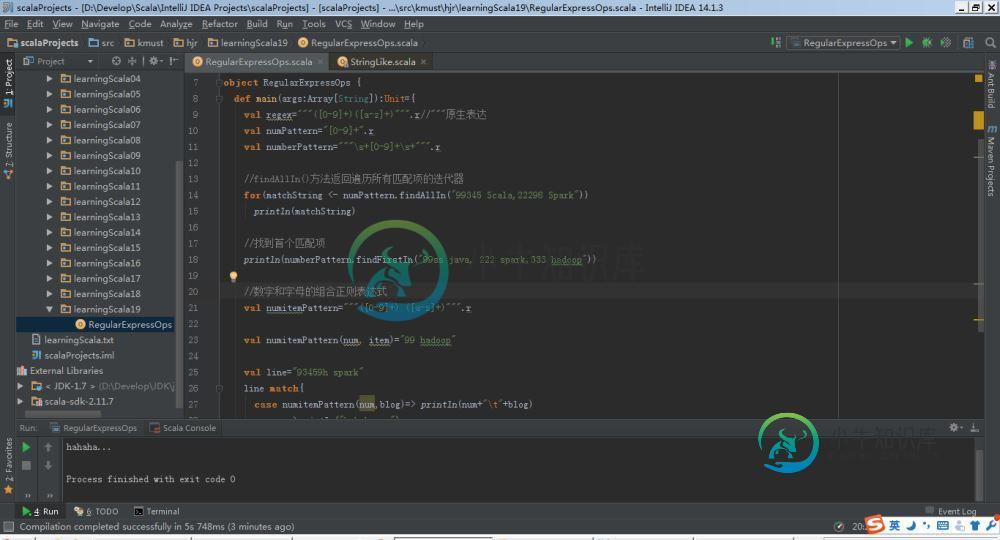
本节所有程序源码
package kmust.hjr.learningScala19
/**
* Created by Administrator on 2015/10/17.
*/
object RegularExpressOps {
def main(args:Array[String]):Unit={
val regex="""([0-9]+)([a-z]+)""".r//"""原生表达
val numPattern="[0-9]+".r
val numberPattern="""\s+[0-9]+\s+""".r
//findAllIn()方法返回遍历所有匹配项的迭代器
for(matchString <- numPattern.findAllIn("99345 Scala,22298 Spark"))
println(matchString)
//找到首个匹配项
println(numberPattern.findFirstIn("99ss java, 222 spark,333 hadoop"))
//数字和字母的组合正则表达式
val numitemPattern="""([0-9]+) ([a-z]+)""".r
val numitemPattern(num, item)="99 hadoop"
val line="93459h spark"
line match{
case numitemPattern(num,blog)=> println(num+"\t"+blog)
case _=>println("hahaha...")
}
}
}
总结
以上所述是小编给大家介绍的Scala中正则表达式以及与模式匹配结合(多种方式),希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
-
有没有一种方法可以在python中编写与以下格式的字符串匹配的正则表达式: 或 在这里,$=表示零或更多的空白可以存在 :来自字符串的固定子集的字符串['feat','fix','docs','断'] :最大长度为n的字符串 :最大长度为m的字符串 前缀应该始终是一个字符串,之后是一些最大q长度的字母数字字符 注意:我们不能省略像应该使用与下面示例中所示完全相同的格式: feat(feat new
-
有没有人试图描述与正则表达式匹配的正则表达式? 由于重复的关键字,这个主题几乎不可能在网上找到。 它可能在实际应用程序中不可用,因为支持正则表达式的语言通常具有解析它们的方法,我们可以将其用于验证,以及一种在代码中分隔正则表达式的方法,可用于搜索目的。 但是我仍然想知道匹配所有正则表达式的正则表达式是什么样子的。应该可以写一个。
-
我有一根线,比如: 如何匹配每行的最后一个?顺便说一句,这是我试图在Sublime的文本中做到的。这些值不一致,就像我在这里看到的,我有几百行要替换。 我尝试了,但这与相匹配。
-
我的目标是以优雅的方式将几个正则表达式模式匹配到同一个字符串。我知道有必要使用组来进行这种类型的正则表达式匹配,并且为了使用下面的匹配功能,我需要在语句中显式捕获这些组中的每一个(例如,两个组在语句中需要两个)。 现在,我有以下几点考虑: 从下划线的使用中可以明显看出,我不关心捕捉模式的特定组,只关心任何第一个匹配。 我的实际模式非常复杂,因此为了可管理性,我更愿意将它们保留为单独的对象,而不是将
-
本文向大家介绍正则表达式模式匹配的String方法,包括了正则表达式模式匹配的String方法的使用技巧和注意事项,需要的朋友参考一下 在JavaScript代码中使用正则表达式进行模式匹配经常会用到String对象和RegExp对象的一些方法,例如replace、match、search等方法,以下是对一些方法使用的总结。 String对象中支持正则表达式有4种方法,分别是:search、rep
-
问题内容: 我有一个输入字符串。 我正在考虑如何有效地将此字符串与多个正则表达式匹配。 我想针对这些正则表达式模式进行匹配,如果其中至少一种匹配则返回: 我不确定如何一次匹配多种模式。有人可以告诉我我们如何有效地做到这一点吗? 问题答案: 如果只有几个正则表达式,并且在编译时都知道它们,那么这就足够了: 如果它们更多,或者它们在运行时加载,则使用模式列表: