
JVM代码缓存区CodeCache原理及用法解析

一. CodeCache简介
从字面意思理解就是代码缓存区,它缓存的是JIT(Just in Time)编译器编译的代码,简言之codeCache是存放JIT生成的机器码(native code)。当然JNI(Java本地接口)的机器码也放在codeCache里,不过JIT编译生成的native code占主要部分。
大致在JVM中的分布如下:
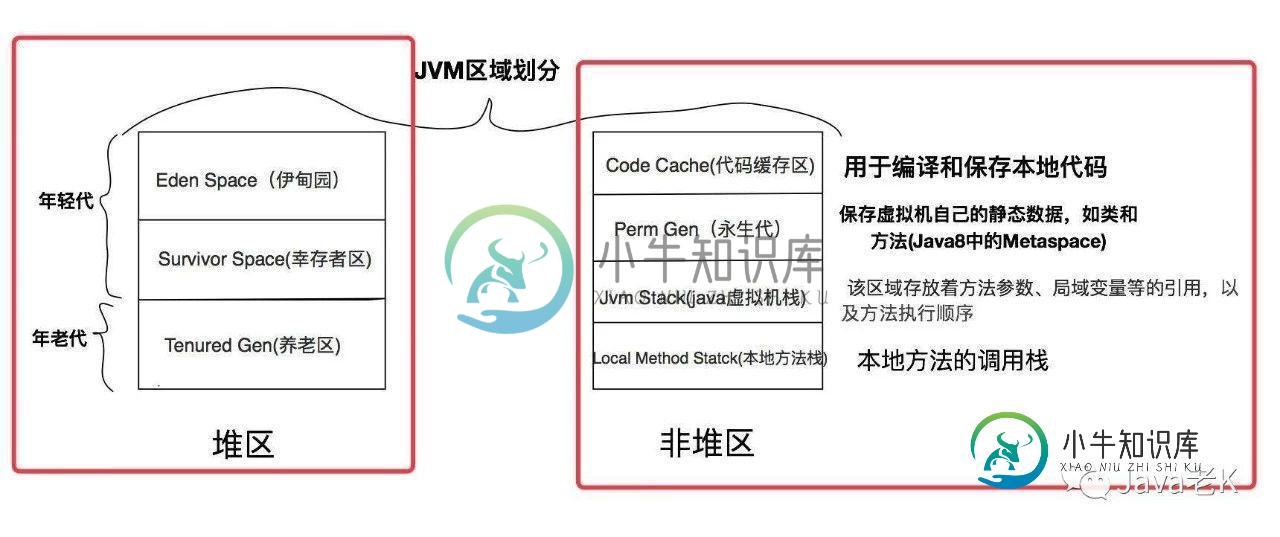
大家都知道javac编译器,把java代码编译成class字节码,它和JIT编译器的区别是,javac只是前端编译(有的叫前期编译),jvm是通过执行机器码和底层交互的,这样我们编写的业务代码才能生效。所以还要把字节码class编译成与本地平台相关的机器码,这个过程就是后端编译。
后端编译根据具体的执行方式不同又分为两种:
1.解释执行
一行一行解释成机器码再执行,每次调用时都需要重新逐条解释执行。
2.编译执行(JIT)
将频繁调用的方法或循环体编译成机器码后,进行多层优化,然后缓存到codeCache里,避免重复编译。
两种执行方式的区别很明显,第一种在遇到频繁调用的方法或代码块时执行效率很低,但是解释执行可以节省内存(不存放到codeCache),立即执行。然后当程序运行一段时间后(达到一定的编译次数),编译执行即JIT优化,可以获得更高的执行效率。
所以说二者是相辅相成的。
现在的Java虚拟机这两种方式都包含(通过命令行java -version查看):
// mixed mode 解释+编译
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
其实JIT编译只是一个统称,具体要看jvm是client端还是server端的,不同的端会分为C1,C2编译器,这两种编译器的区别下一篇会讲到,这里先不展开。
二. JIT编译优化
上面讲到了JVM会对频繁使用的代码,即热点代码(Hot Spot Code),达到一定的阈值后会编译成本地平台相关的机器码,并进行各层次的优化,提升执行效率。
热点代码也分两种:
- 被多次调用的方法
- 被多次执行的循环体
那阈值如何判断呢?
方法计数器,统计被多次调用的方法次数,该计数器统计的并不是方法被调用的绝对次数,而是在一段时间内方法被调用的次数。server模式下默认是10000次,可以通过-XX:CompileThreshold来设置(client模式一般很少用到,默认是1500)。
回边计数器,统计一个方法中循环体代码执行的绝对次数,在字节码中遇到控制流向后跳转的指令称为回边,主要通过OnStackReplacePercentage设置。
编译后进行优化,JIT的优化有很多种,比如:
- 针对方法的优化,方法内联
- 针对多次调用的循环体优化:栈上替换OSR(On-Stack Replace)
- 无用代码消除
- 复写传播
- 逃逸分析
- 更多JIT优化技术可参考jvm官网介绍
三. codeCache使用注意事项
上面主要讲了codeCache的作用和JIT的关系,codeCache主要是存放JIT编译后的机器代码,codeCache的大小主要是通过下面的参数设置:
- -XX:InitialCodeCacheSize 设置codeCache初始大小,一般默认是48M
- -XX:ReservedCodeCacheSize 设置codeCache预留的大小,通常默认是240M
如果codeCache的内存满了会进行回收,但在jdk1.8之前的jvm回收算法有点问题,当codeCache满了之后会导致编译线程无法继续,并且消耗大量CPU导致系统运行变慢,现象就是系统响应增加,如果你也遇到这个问题建议直接升级成jdk8,或者调大codeCache内存。
codeCache的大小设置可以通过-XX:+PrintCodeCache参数查看调整,但这个参数只在JVM停止的时候打印codeCache使用情况,所以如果想实时监控codeCache的使用情况,可以参考如下代码:
package com.javakk;
import java.io.File;
import java.lang.management.ManagementFactory;
import javax.management.MBeanServerConnection;
import javax.management.ObjectName;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
import com.sun.tools.attach.VirtualMachine;
/**
* 基于JMX在运行时查看codeCache使用情况
* @author 公众号:Java老K
*/
public class CodeCacheTest {
public static void main(String[] args) throws Exception {
String pid = getPid(); // 先获取java程序的pid
String codeCache = getCodeCache(pid); // 根据pid获取codeCache的使用情况
System.out.println(codeCache);
}
/**
* 获取java进程id
* @return
*/
public static String getPid(){
String name = ManagementFactory.getRuntimeMXBean().getName();
return name.split("@")[0];
}
/**
* 获取java应用的codeCache使用情况
* @param pid
* @throws Exception
*/
public static String getCodeCache(String pid) throws Exception {
VirtualMachine vm = VirtualMachine.attach(pid);
JMXConnector connector = null;
try {
String addr = "com.sun.management.jmxremote.localConnectorAddress";
String property= vm.getAgentProperties().getProperty(addr);
if (property == null) {
String agent = vm.getSystemProperties().getProperty("java.home")
+ File.separator
+ "lib"
+ File.separator
+ "management-agent.jar";
vm.loadAgent(agent);
property = vm.getAgentProperties().getProperty(addr);
}
JMXServiceURL url = new JMXServiceURL(property);
connector = JMXConnectorFactory.connect(url);
MBeanServerConnection mbeanConn = connector.getMBeanServerConnection();
ObjectName obj = new ObjectName("java.lang:type=MemoryPool,name=Code Cache");
return mbeanConn.getAttribute(obj, "Usage").toString();
} finally {
if(connector != null) {
connector.close();
}
vm.detach();
}
}
}
运行后可以查看contents结果
contents={committed=2555904, init=2555904, max=251658240, used=2395648}
可以看到我本地的codeCahe配置,初始化是2555904,最大为251658240,已使用2395648
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python代码块及缓存机制原理详解,包括了Python代码块及缓存机制原理详解的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Python代码块及缓存机制原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.相同的字符串在Python中地址相同 2.代码块: 所有的代码都需要依赖代码块执行。 一个模块,一个函
-
本文向大家介绍MyBatis缓存实现原理及代码实例解析,包括了MyBatis缓存实现原理及代码实例解析的使用技巧和注意事项,需要的朋友参考一下 一、一级缓存(本地缓存) sqlSession级别的缓存。一级缓存是一直开启的;SqlSession级别的一个Map与数据库同一次会话期间查询到的数据会放在本地缓存中。以后如果需要获取相同的数据,直接从缓存中拿,没必要再去查询数据库; 一级缓存失效
-
本文向大家介绍Mybatis 缓存原理及失效情况解析,包括了Mybatis 缓存原理及失效情况解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Mybatis 缓存原理及失效情况解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1、什么是缓存[Cache] 存在内存中的临时数据。 将用户经常查询的数据放在缓存(内存)中,用户去查询
-
本文向大家介绍MyBatis缓存功能原理及实例解析,包括了MyBatis缓存功能原理及实例解析的使用技巧和注意事项,需要的朋友参考一下 缓存 1、简介 查询 : 连接数据库,耗资源! 一次查询的结果,给他暂存在一个可以直接取到的地方!--->内存 : 缓存 我们再次查询相同数据的时候,直接走缓存,就不用走数据库了 什么是缓存: 存在内存中的临时数据 将用户经常查询的数据放在缓存(内存)中,用户去查
-
本文向大家介绍Js on及addEventListener原理用法区别解析,包括了Js on及addEventListener原理用法区别解析的使用技巧和注意事项,需要的朋友参考一下 一.首先介绍两者的用法: 1.on的用法:以onclick为例 第一种: 第二种: 第三种:当函数fn有参数的情况下使用匿名函数来传参: 不能够这样写:错误写法:obj.onclick= fn(param): 因为这
-
本文向大家介绍Python threading.local代码实例及原理解析,包括了Python threading.local代码实例及原理解析的使用技巧和注意事项,需要的朋友参考一下 Python的线程操作在旧版本中使用的是thread模块,在Python27和Python3中引入了threading模块,同时thread模块在Python3中改名为_thread模块,threading模块相