
Android7.0 MessageQueue详解

Android中的消息处理机制大量依赖于Handler。每个Handler都有对应的Looper,用于不断地从对应的MessageQueue中取出消息处理。
一直以来,觉得MessageQueue应该是Java层的抽象,然而事实上MessageQueue的主要部分在Native层中。
自己对MessageQueue在Native层的工作不太熟悉,借此机会分析一下。
一、MessageQueue的创建
当需要使用Looper时,我们会调用Looper的prepare函数:
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
//sThreadLocal为线程本地存储区;每个线程仅有一个Looper
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
//创建出MessageQueue
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
1 NativeMessageQueue
我们看看MessageQueue的构造函数:
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
//mPtr的类型为long?
mPtr = nativeInit();
}
MessageQueue的构造函数中就调用了native函数,我们看看android_os_MessageQueue.cpp中的实现:
static jlong android_os_MessageQueue_nativeInit(JNIEnv* env, jclass clazz) {
//MessageQueue的Native层实体
NativeMessageQueue* nativeMessageQueue = new NativeMessageQueue();
............
//这里应该类似与将指针转化成long类型,放在Java层保存;估计Java层使用时,会在native层将long变成指针,就可以操作队列了
return reinterpret_cast<jlong>(nativeMessageQueue);
}
我们跟进NativeMessageQueue的构造函数:
NativeMessageQueue::NativeMessageQueue() :
mPollEnv(NULL), mPollObj(NULL), mExceptionObj(NULL) {
//创建一个Native层的Looper,也是线程唯一的
mLooper = Looper::getForThread();
if (mLooper == NULL) {
mLooper = new Looper(false);
Looper::setForThread(mLooper);
}
}
从代码来看,Native层和Java层均有Looper对象,应该都是操作MessageQueue的。MessageQueue在Java层和Native层有各自的存储结构,分别存储Java层和Native层的消息。
2 Native层的looper
我们看看Native层looper的构造函数:
Looper::Looper(bool allowNonCallbacks) :
mAllowNonCallbacks(allowNonCallbacks), mSendingMessage(false),
mPolling(false), mEpollFd(-1), mEpollRebuildRequired(false),
mNextRequestSeq(0), mResponseIndex(0), mNextMessageUptime(LLONG_MAX) {
//此处创建了个fd
mWakeEventFd = eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC);
.......
rebuildEpollLocked();
}
在native层中,MessageQueue中的Looper初始化时,还调用了rebuildEpollLocked函数,我们跟进一下:
void Looper::rebuildEpollLocked() {
// Close old epoll instance if we have one.
if (mEpollFd >= 0) {
close(mEpollFd);
}
// Allocate the new epoll instance and register the wake pipe.
mEpollFd = epoll_create(EPOLL_SIZE_HINT);
............
struct epoll_event eventItem;
memset(& eventItem, 0, sizeof(epoll_event)); // zero out unused members of data field union
eventItem.events = EPOLLIN;
eventItem.data.fd = mWakeEventFd;
//在mEpollFd上监听mWakeEventFd上是否有数据到来
int result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeEventFd, & eventItem);
...........
for (size_t i = 0; i < mRequests.size(); i++) {
const Request& request = mRequests.valueAt(i);
struct epoll_event eventItem;
request.initEventItem(&eventItem);
//监听request对应fd上数据的到来
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, request.fd, & eventItem);
............
}
}
从native层的looper来看,我们知道Native层依赖于epoll来驱动事件处理。此处我们先保留一下大致的映像,后文详细分析。
二、使用MessageQueue
1 写入消息
Android中既可以在Java层向MessageQueue写入消息,也可以在Native层向MessageQueue写入消息。我们分别看一下对应的操作流程。
1.1 Java层写入消息
Java层向MessageQueue写入消息,依赖于enqueueMessage函数:
boolean enqueueMessage(Message msg, long when) {
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
synchronized (this) {
if (mQuitting) {
.....
return false;
}
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
//在头部插入数据,如果之前MessageQueue是阻塞的,那么现在需要唤醒
needWake = mBlocked;
} else {
// Inserted within the middle of the queue. Usually we don't have to wake
// up the event queue unless there is a barrier at the head of the queue
// and the message is the earliest asynchronous message in the queue.
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
//不是第一个异步消息时,needWake置为false
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
// We can assume mPtr != 0 because mQuitting is false.
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
上述代码比较简单,主要就是将新加入的Message按执行时间插入到原有的队列中,然后根据情况调用nativeAwake函数。
我们跟进一下nativeAwake:
void NativeMessageQueue::wake() {
mLooper->wake();
}
void Looper::wake() {
uint64_t inc = 1;
//就是向mWakeEventFd写入数据
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd, &inc, sizeof(uint64_t)));
.............
}
在native层的looper初始化时,我们提到过native层的looper将利用epoll来驱动事件,其中构造出的epoll句柄就监听了mWakeEventFd。
实际上从MessageQueue中取出数据时,若没有数据到来,就会利用epoll进行等待;因此当Java层写入消息时,将会将唤醒处于等待状态的MessageQueue。
在后文介绍从MessageQueue中提取消息时,将再次分析这个问题。
1.2 Native层写入消息
Native层写入消息,依赖于Native层looper的sendMessage函数:
void Looper::sendMessage(const sp<MessageHandler>& handler, const Message& message) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
sendMessageAtTime(now, handler, message);
}
void Looper::sendMessageAtTime(nsecs_t uptime, const sp<MessageHandler>& handler,
const Message& message) {
size_t i = 0;
{
AutoMutex _l(mLock);
//同样需要按时间插入
size_t messageCount = mMessageEnvelopes.size();
while (i < messageCount && uptime >= mMessageEnvelopes.itemAt(i).uptime) {
i += 1;
}
//将message包装成一个MessageEnvelope对象
MessageEnvelope messageEnvelope(uptime, handler, message);
mMessageEnvelopes.insertAt(messageEnvelope, i, 1);
// Optimization: If the Looper is currently sending a message, then we can skip
// the call to wake() because the next thing the Looper will do after processing
// messages is to decide when the next wakeup time should be. In fact, it does
// not even matter whether this code is running on the Looper thread.
if (mSendingMessage) {
return;
}
}
// Wake the poll loop only when we enqueue a new message at the head.
if (i == 0) {
//若插入在队列头部,同样利用wake函数触发epoll唤醒
wake();
}
}
以上就是向MessageQueue中加入消息的主要流程,接下来我们看看从MessageQueue中取出消息的流程。
2、提取消息
当Java层的Looper对象调用loop函数时,就开始使用MessageQueue提取消息了:
public static void loop() {
final Looper me = myLooper();
.......
for (;;) {
Message msg = queue.next(); // might block
.......
try {
//调用Message的处理函数进行处理
msg.target.dispatchMessage(msg);
}........
}
}
此处我们看看MessageQueue的next函数:
Message next() {
//mPtr保存了NativeMessageQueue的指针
final long ptr = mPtr;
.......
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
//会调用Native函数,最终调用IPCThread的talkWithDriver,将数据写入Binder驱动或者读取一次数据
//不知道在此处进行这个操作的理由?
Binder.flushPendingCommands();
}
//处理native层的数据,此处会利用epoll进行blocked
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
//下面其实就是找出下一个异步处理类型的消息;异步处理类型的消息,才含有对应的执行函数
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
//完成next记录的存储
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
// Process the quit message now that all pending messages have been handled.
if (mQuitting) {
dispose();
return null;
}
//MessageQueue中引入了IdleHandler接口,即当MessageQueue没有数据处理时,调用IdleHandler进行一些工作
//pendingIdleHandlerCount表示待处理的IdleHandler,初始为-1
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
//mIdleHandlers的size默认为0,调用接口addIdleHandler才能增加
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
//将待处理的IdleHandler加入到PendingIdleHandlers中
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
//调用ArrayList.toArray(T[])节省每次分配的开销;毕竟对于Message.Next这样调用频率较高的函数,能省一点就是一点
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
//执行实现类的queueIdle函数,返回值决定是否继续保留
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
pendingIdleHandlerCount = 0;
nextPollTimeoutMillis = 0;
}
}
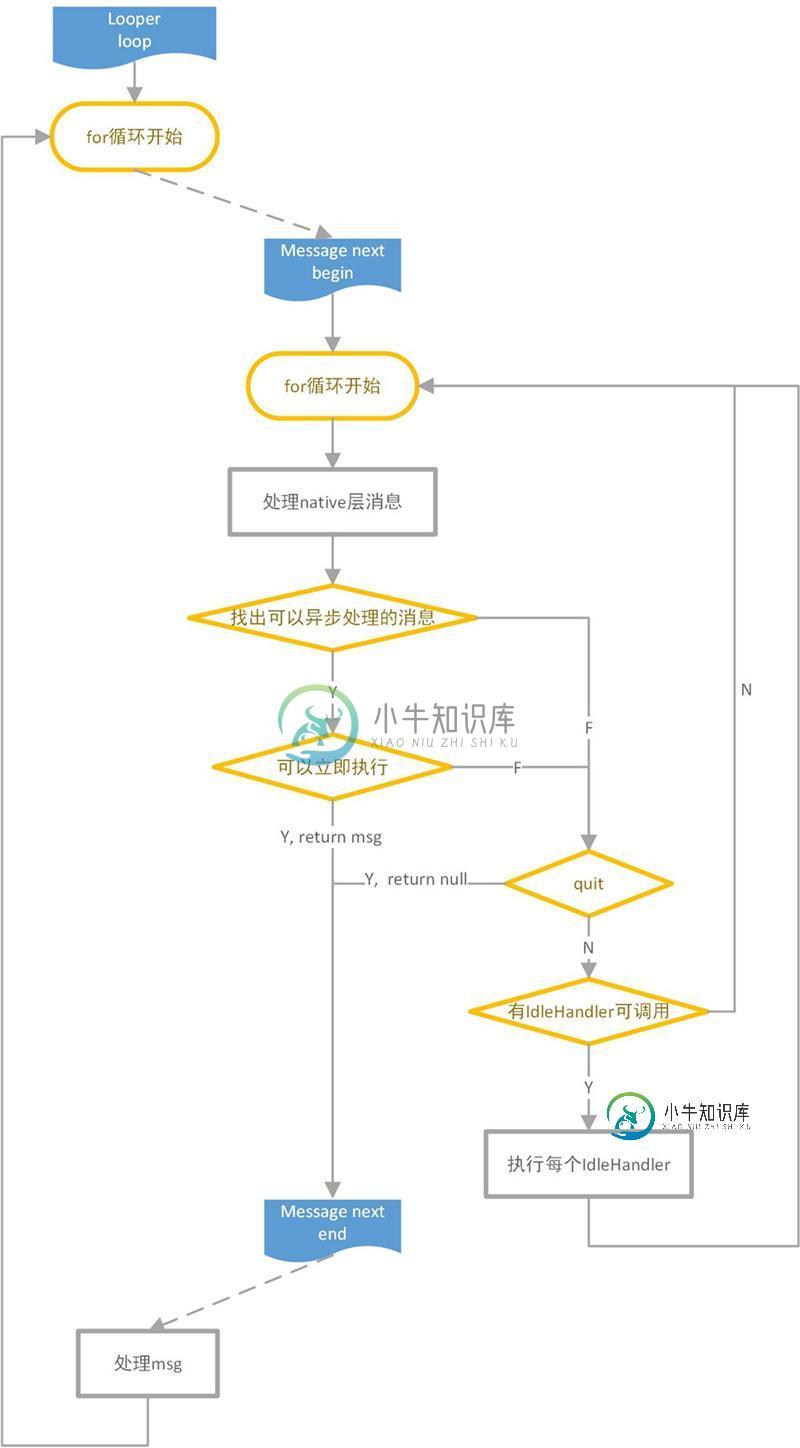
整个提取消息的过程,大致上如上图所示。
可以看到在Java层,Looper除了要取出MessageQueue的消息外,还会在队列空闲期执行IdleHandler定义的函数。
2.1 nativePollOnce
现在唯一的疑点是nativePollOnce是如何处理Native层数据的,我们看看对应的native函数:
static void android_os_MessageQueue_nativePollOnce(JNIEnv* env, jobject obj,
jlong ptr, jint timeoutMillis) {
//果然Java层调用native层MessageQueue时,将long类型的ptr变为指针
NativeMessageQueue* nativeMessageQueue = reinterpret_cast<NativeMessageQueue*>(ptr);
nativeMessageQueue->pollOnce(env, obj, timeoutMillis);
}
void NativeMessageQueue::pollOnce(JNIEnv* env, jobject pollObj, int timeoutMillis) {
mPollEnv = env;
mPollObj = pollObj;
//最后还是进入到Native层looper的pollOnce函数
mLooper->pollOnce(timeoutMillis);
mPollObj = NULL;
mPollEnv = NULL;
if (mExceptionObj) {
.........
}
}
看看native层looper的pollOnce函数:
//timeoutMillis为超时等待时间。值为-1时,表示无限等待直到有事件到来;值为0时,表示无需等待
//outFd此时为null,含义是:存储产生事件的文件句柄
//outEvents此时为null,含义是:存储outFd上发生了哪些事件,包括可读、可写、错误和中断
//outData此时为null,含义是:存储上下文数据,其实调用时传入的参数
int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData) {
int result = 0;
for (;;) {
//处理response,目前我们先不关注response的内含
while (mResponseIndex < mResponses.size()) {
const Response& response = mResponses.itemAt(mResponseIndex++);
int ident = response.request.ident;
if (ident >= 0) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
if (outFd != NULL) *outFd = fd;
if (outEvents != NULL) *outEvents = events;
if (outData != NULL) *outData = data;
return ident;
}
}
//根据pollInner的结果,进行操作
if (result != 0) {
if (outFd != NULL) *outFd = 0;
if (outEvents != NULL) *outEvents = 0;
if (outData != NULL) *outData = NULL;
return result;
}
//主力还是靠pollInner
result = pollInner(timeoutMillis);
}
}
跟进一下pollInner函数:
int Looper::pollInner(int timeoutMillis) {
// Adjust the timeout based on when the next message is due.
//timeoutMillis是Java层事件等待事件
//native层维持了native message的等待时间
//此处其实就是选择最小的等待时间
if (timeoutMillis != 0 && mNextMessageUptime != LLONG_MAX) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
int messageTimeoutMillis = toMillisecondTimeoutDelay(now, mNextMessageUptime);
if (messageTimeoutMillis >= 0
&& (timeoutMillis < 0 || messageTimeoutMillis < timeoutMillis)) {
timeoutMillis = messageTimeoutMillis;
}
}
int result = POLL_WAKE;
//pollInner初始就清空response
mResponses.clear();
mResponseIndex = 0;
// We are about to idle.
mPolling = true;
//利用epoll等待mEpollFd监控的句柄上事件到达
struct epoll_event eventItems[EPOLL_MAX_EVENTS];
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
// No longer idling.
mPolling = false;
// Acquire lock.
mLock.lock();
//重新调用rebuildEpollLocked时,将使得epoll句柄能够监听新加入request对应的fd
if (mEpollRebuildRequired) {
mEpollRebuildRequired = false;
rebuildEpollLocked();
goto Done;
}
// Check for poll error.
if (eventCount < 0) {
if (errno == EINTR) {
goto Done;
}
......
result = POLL_ERROR;
goto Done;
}
// Check for poll timeout.
if (eventCount == 0) {
result = POLL_TIMEOUT;
goto Done;
}
for (int i = 0; i < eventCount; i++) {
if (fd == mWakeEventFd) {
if (epollEvents & EPOLLIN) {
//前面已经分析过,当java层或native层有数据写入队列时,将写mWakeEventFd,以触发epoll唤醒
//awoken将读取并清空mWakeEventFd上的数据
awoken();
} else {
.........
}
} else {
//epoll同样监听的request对应的fd
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex >= 0) {
int events = 0;
if (epollEvents & EPOLLIN) events |= EVENT_INPUT;
if (epollEvents & EPOLLOUT) events |= EVENT_OUTPUT;
if (epollEvents & EPOLLERR) events |= EVENT_ERROR;
if (epollEvents & EPOLLHUP) events |= EVENT_HANGUP;
//存储这个fd对应的response
pushResponse(events, mRequests.valueAt(requestIndex));
} else {
..........
}
}
}
Done:
// Invoke pending message callbacks.
mNextMessageUptime = LLONG_MAX;
//处理Native层的Message
while (mMessageEnvelopes.size() != 0) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
const MessageEnvelope& messageEnvelope = mMessageEnvelopes.itemAt(0);
if (messageEnvelope.uptime <= now) {
// Remove the envelope from the list.
// We keep a strong reference to the handler until the call to handleMessage
// finishes. Then we drop it so that the handler can be deleted *before*
// we reacquire our lock.
{
sp<MessageHandler> handler = messageEnvelope.handler;
Message message = messageEnvelope.message;
mMessageEnvelopes.removeAt(0);
mSendingMessage = true;
mLock.unlock();
//处理Native Message
handler->handleMessage(message);
}
mLock.lock();
mSendingMessage = false;
result = POLL_CALLBACK;
} else {
// The last message left at the head of the queue determines the next wakeup time.
mNextMessageUptime = messageEnvelope.uptime;
break;
}
}
// Release lock.
mLock.unlock();
//处理带回调函数的response
for (size_t i = 0; i < mResponses.size(); i++) {
Response& response = mResponses.editItemAt(i);
if (response.request.ident == POLL_CALLBACK) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
//调用response的callback
int callbackResult = response.request.callback->handleEvent(fd, events, data);
if (callbackResult == 0) {
removeFd(fd, response.request.seq);
}
response.request.callback.clear();
result = POLL_CALLBACK;
}
}
return result;
}
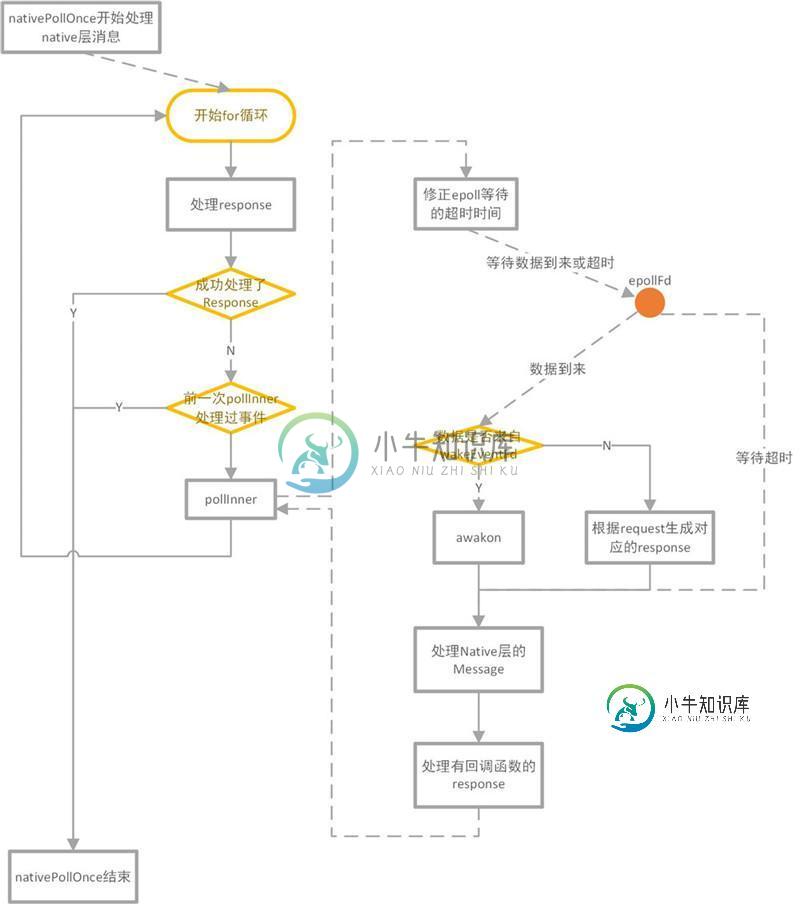
说实话native层的代码写的很乱,该函数的功能比较多。
如上图所示,在nativePollOnce中利用epoll监听是否有数据到来,然后处理native message、native response。
最后,我们看看如何在native层中加入request。
3 添加监控请求
native层增加request依赖于looper的接口addFd:
//fd表示需要监听的句柄 //ident的含义还没有搞明白 //events表示需要监听的事件,例如EVENT_INPUT、EVENT_OUTPUT、EVENT_ERROR和EVENT_HANGUP中的一个或多个 //callback为事件发生后的回调函数 //data为回调函数对应的参数 int Looper::addFd(int fd, int ident, int events, Looper_callbackFunc callback, void* data) { return addFd(fd, ident, events, callback ? new SimpleLooperCallback(callback) : NULL, data); }
结合上文native层轮询队列的操作,我们大致可以知道:addFd的目的,就是让native层的looper监控新加入的fd上是否有指定事件发生。
如果发生了指定的事件,就利用回调函数及参数构造对应的response。
native层的looper处理response时,就可以执行对应的回调函数了。
看看实际的代码:
int Looper::addFd(int fd, int ident, int events, const sp<LooperCallback>& callback, void* data) {
........
{
AutoMutex _l(mLock);
//利用参数构造一个request
Request request;
request.fd = fd;
request.ident = ident;
request.events = events;
request.seq = mNextRequestSeq++;
request.callback = callback;
request.data = data;
if (mNextRequestSeq == -1) mNextRequestSeq = 0; // reserve sequence number -1
struct epoll_event eventItem;
request.initEventItem(&eventItem);
//判断之前是否已经利用该fd构造过Request
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex < 0) {
//mEpollFd新增一个需监听fd
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, fd, & eventItem);
.......
mRequests.add(fd, request);
} else {
//mEpollFd修改旧的fd对应的监听事件
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_MOD, fd, & eventItem);
if (epollResult < 0) {
if (errno == ENOENT) {
// Tolerate ENOENT because it means that an older file descriptor was
// closed before its callback was unregistered and meanwhile a new
// file descriptor with the same number has been created and is now
// being registered for the first time.
epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, fd, & eventItem);
.......
}
//发生错误重新加入时,安排EpollRebuildLocked,将让epollFd重新添加一次待监听的fd
scheduleEpollRebuildLocked();
}
mRequests.replaceValueAt(requestIndex, request);
}
}
}
对加入监控请求的处理,在上文介绍pollInner函数时已做分析,此处不再赘述。
三、总结
1、流程总结
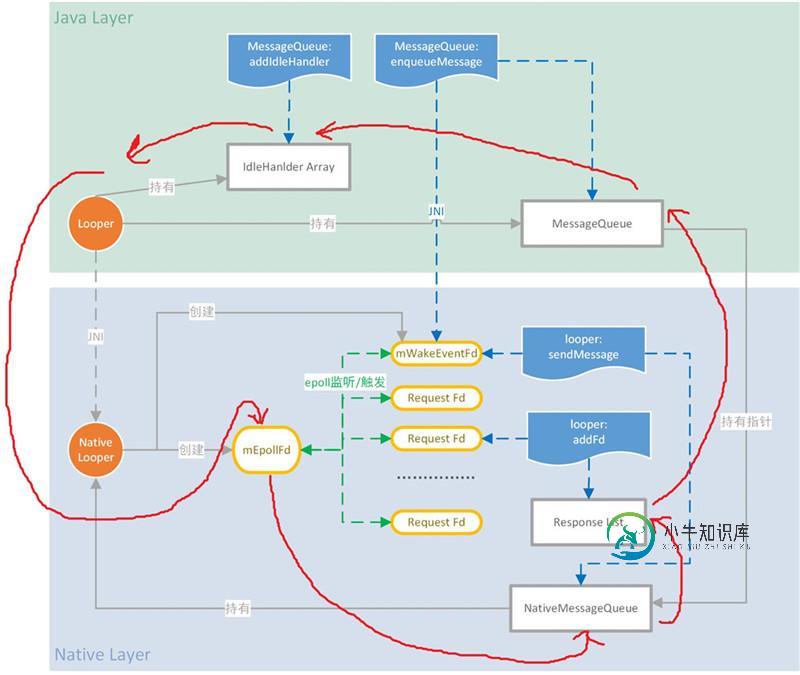
MessageQueue的整个流程包括了Java部分和Native部分,从图中可以看出Native层的比重还是很大的。我们结合上图回忆一下整个MessageQueue对应的处理流程:
1、Java层创建Looper对象时,将会创建Java层的MessageQueue;Java层的MessageQueue初始化时,将利用Native函数创建出Native层的MessageQueue。
2、Native层的MessageQueue初始化后,将创建对应的Native Looper对象。Native对象初始化时,将创建对应epollFd和WakeEventFd。其中,epollFd将作为epoll的监听句柄,初始时epollFd仅监听WakeEventFd。
3、图中红色线条为Looper从MessageQueue中取消息时,处理逻辑的流向。
3.1、当Java层的Looper开始循环时,首先需要通过JNI函数调用Native Looper进行pollOnce的操作。
3.2、Native Looper开始运行后,需要等待epollFd被唤醒。当epollFd等待超时或监听的句柄有事件到来,Native Looper就可以开始处理事件了。
3.3、在Native层,Native Looper将先处理Native MessageQueue中的消息,再调用Response对应的回调函数。
3.4、本次循环中,Native层事件处理完毕后,才开始处理Java层中MessageQueue的消息。若MessageQueue中没有消息需要处理,并且MessageQueue中存在IdleHandler时,将调用IdleHandler定义的处理函数。
图中蓝色部分为对应的函数调用:
在Java层:
利用MessageQueue的addIdleHandler,可以为MessageQueue增加IdleHandler;
利用MessageQueue的enqueueMessage,可以向MessageQueue增加消息;必要时将利用Native函数向Native层的WakeEventFd写入消息,以唤醒epollFd。
在Native层:
利用looper:sendMessage,可以为Native MessageQueue增加消息;同样,要时将向Native层的WakeEventFd写入消息,以唤醒epollFd;
利用looper:addFd,可以向Native Looper注册监听请求,监听请求包含需监听的fd、监听的事件及对应的回调函数等,监听请求对应的fd将被成为epollFd监听的对象。当被监听的fd发生对应的事件后,将会唤醒epollFd,此时将生成对应response加入的response List中,等待处理。一旦response被处理,就会调用对应的回调函数。
2、注意事项
MessageQueue在Java层和Native层有各自的存储结构,可以分别增加消息。从处理逻辑来看,会优先处理native层的Message,然后处理Native层生成的response,最后才是处理Java层的Message。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍awk 详解。相关面试题,主要包含被问及awk 详解。时的应答技巧和注意事项,需要的朋友参考一下 答案: awk '{pattern + action}' { filenames } #cat /etc/passwd |awk -F ':' '{print 1"t"7}' //-F 的意思是以':'分隔 root /bin/bash daemon /bin/sh 搜索/etc/pas
-
glob 是由普通字符和/或通配字符组成的字符串,用于匹配文件路径。可以利用一个或多个 glob 在文件系统中定位文件。 src() 方法接受一个 glob 字符串或由多个 glob 字符串组成的数组作为参数,用于确定哪些文件需要被操作。glob 或 glob 数组必须至少匹配到一个匹配项,否则 src() 将报错。当使用 glob 数组时,将按照每个 glob 在数组中的位置依次执行匹配 - 这
-
scanf()函数详解 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> //01.scanf();函数扫描输入事项: // 格式必须一一匹配:非格式控制符的可见字符必须一一匹配输入 int main01(void) { int num = 0; printf("%p \n", &nu
-
printf()详解 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> //01.printf();&sprintf();&fprintf();格式控制字符串详解: // (1).格式控制字符串的组成: // 普通字符串+格式控制符 // (2).常见的格式控制字符: // %f-
-
主要内容:state状态,自定义资源共享方式,源码实现AQS是AbstractQueuedSynchronizer的简称。AQS提供了一种实现阻塞锁和一系列依赖FIFO等待队列的同步器的框架,如下图所示。AQS为一系列同步器依赖于一个单独的原子变量(state)的同步器提供了一个非常有用的基础。子类们必须定义改变state变量的protected方法,这些方法定义了state是如何被获取或释放的。鉴于此,本类中的其他方法执行所有的排队和阻塞机制。子类
-
主要内容:state状态,自定义资源共享方式,源码实现AQS是AbstractQueuedSynchronizer的简称。AQS提供了一种实现阻塞锁和一系列依赖FIFO等待队列的同步器的框架,如下图所示。AQS为一系列同步器依赖于一个单独的原子变量(state)的同步器提供了一个非常有用的基础。子类们必须定义改变state变量的protected方法,这些方法定义了state是如何被获取或释放的。鉴于此,本类中的其他方法执行所有的排队和阻塞机制。子类
-
主要内容:6 DataNode(面试开发重点)6 DataNode(面试开发重点) 6.1 DataNode工作机制 DataNode工作机制,如图3-15所示。 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。 2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。 3)心跳是每3秒一次
-
主要内容:4 HDFS的数据流,5 NameNode和SecondaryNameNode(面试开发重点)4 HDFS的数据流 4.1 HDFS写数据流程 4.1.1 剖析文件写入 HDFS写数据流程 1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 2)NameNode返回是否可以上传。 3)客户端请求第一个 Block上传到哪几个DataNode服务器上。 4)NameNode返回3个Data