
python3.7 openpyxl 在excel单元格中写入数据实例

本来我是想尝试,选中某个多个单元格复制到同一个sheet的其他位置,找了很多资料没有找到,目前只有这么一个办法,如果有大佬看到,欢迎补充请教。
# encoding:utf-8 import pandas as pd import openpyxl xl = pd.read_excel(r"E:\55\CRM经营分析表-10001741-1570416265044.xls") xl.to_excel(r"E:\55\crms.xlsx") wk = openpyxl.load_workbook(r"E:\55\crms.xlsx") #加载已经存在的excel wk_name = wk.sheetnames wk_sheet = wk[wk_name[0]] wk_sheet.cell(row=2,column=2,value='大区') #在第二行,第二列下入“大区”数值 wk_sheet.cell(row=2,column=3,value='小区') wk_sheet.cell(row=2,column=4,value='店铺编码') wk_sheet.cell(row=2,column=5,value='店铺名称') wk.save(r"E:\55\s.xlsx")
补充知识:【openpyxl】python中对Excel进行写入操作,写入一列或者一行(从excel中读出label和feature对应格式方法以及插入一行或者一列方法实现)
前言
最近在做expansion of datset,所以需要把扩展的dataset写入到excel中
我已经矩阵运算全部搞定,最终输出的是两个输出 labels 和 features
自己整理为以下格式
label = [[0],
[1],
[2],
[3]
]
feature = [
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.11, 0.21, 0.31, 0.41, 0.51],
[0.6, 0.7, 0.8, 0.9, 1.00],
[1.1, 1.2, 1.3, 1.4, 1.5],
]
解决方案
先是准备用python带的xlrd xlrd 等包来操作感觉真的不太行
换思路,用第三方包openpyxl来操作
pip install openpyxl
官方文档在这里
https://openpyxl.readthedocs.io/en/stable/index.html
代码
废话不多说,show you my code
# coding=utf-8
from openpyxl import Workbook
import numpy as np
wb = Workbook()
ws = wb.create_sheet("che")
label = [[0],
[1],
[2],
[3]
]
feature = [
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.11, 0.21, 0.31, 0.41, 0.51],
[0.6, 0.7, 0.8, 0.9, 1.00],
[1.1, 1.2, 1.3, 1.4, 1.5],
]
#这个地方之所以 变成numpy格式是因为在很多时候我们都是在numpy格式下计算的,模拟一下预处理
label = np.array(label)
feature = np.array(feature)
label_input = []
for l in range(len(label)):
label_input.append(label[l][0])
ws.append(label_input)
for f in range(len(feature[0])):
ws.append(feature[:, f].tolist())
wb.save("chehongshu.xlsx")
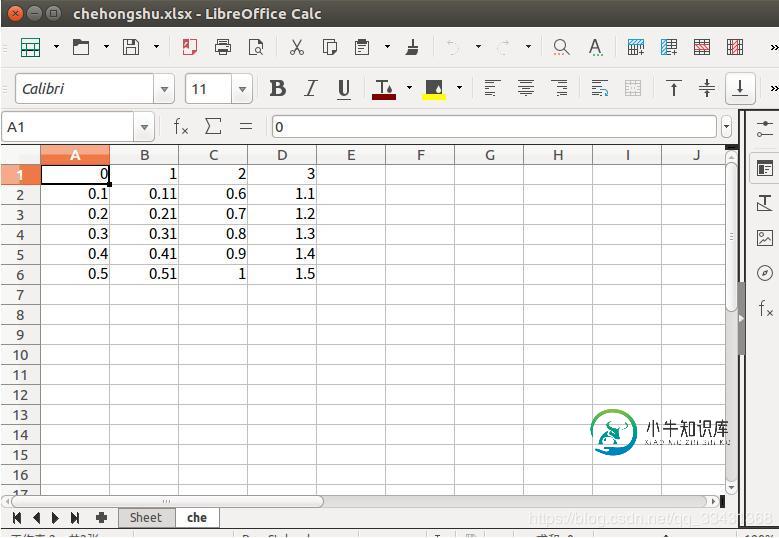
结果生成一个excel,最后结果如下图:
总结
openpyxl包用起来是真的方便,对于写入,只需要建立一个LIST进行append就好了,如果excel为空的那append就从第一行开始递增操作,你也可以理解为一个ws.append()操作就相当于写入一行,如果excel为有数据的时候,那写入操作从没有数据的那一行开始写入;这里也说一下本来想用Insert来着但是忽略了一个条件,就是insert有个前提条件就是For example to insert a row at 7 (before the existing row 7):,意思为插入之前你的数据的大小一定是比要插入的行数或者列数大的,也就是说插入只能插到里面,不能在边缘插。
插入核心参考代码
for col in range(len(label)):
print col
ws.insert_cols(col+1)
for index, row in enumerate(ws.rows):
#print row
if index == 0:
#row[col+1].value = label[col][0]
print "label"
print label[col]
else:
print "feature"
print feature[col][index-1]
#row[col+1].value = feature[col][index-1]
读取代码
def create_data_expansion(path, sheet):
data_init = pd.read_excel(path, sheet)
# print data_init
data_df = pd.DataFrame(data_init)
print data_df
data_df_transponse = data_df.T
label_expansion = np.array(data_df_transponse.index)
label_expansion_l = []
for l in range(len(label_expansion)):
label_expansion_l.append([l])
feature_expansion = np.array(data_df_transponse)
label_expansion = np.array(label_expansion_l)
return label_expansion, feature_expansion
if __name__ == "__main__":
path_name = "excel_demo.xlsx"
sheet_name = "11"
label, feature = create_data_expansion(path_name, sheet_name)
print label
print feature
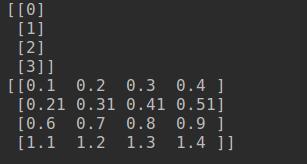
结果:
以上这篇python3.7 openpyxl 在excel单元格中写入数据实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 如何在poi的帮助下在单元格中写下我的全部价值? 即如果值是1000.000,那么我怎么能写出完整的值而不会在“之后”截断000。与POI?表示我想要全部价值。 就我而言,只需要1000,但这对我来说不是正确的格式。 问题答案: 您必须设置要存储此数字的单元格的“格式”。示例代码: 来源:http : //poi.apache.org/spreadsheet/quick- guide.
-
如何使用Apache POI将文本/图像写入特定的合并单元格。特定单元格意味着,我直接将文本或图像写入B3: D7。下面的代码是每个索引的手动代码,而不是单元格的特定名称和数量。我想通过单元格名称和编号放置。
-
我对Eclipse Java编码一无所知。我正在努力完成一个管理库存的项目。我遇到的问题是,当我试图将项目写入excel单元格时,我收到错误消息,称数组超出了界限。 附言:项目和item.get部分名称等都定义在另一个类文件下。请帮忙。谢谢
-
我正在使用Apache POI将Excel函数写入单元格并计算该函数。我需要做的是从单元格中删除所有小数点。目前,它在每个单元格值的末尾得到了不必要的两个零。单元格格式如下所示。但最后总是得到两个零。 我参考了以下URL和其他几个网站,但找不到修复错误的方法。 链接1 链接2 注意我将Apache POI版本3.14与Spring 4.3.1一起使用。释放。
-
本文向大家介绍python实现数据写入excel表格,包括了python实现数据写入excel表格的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python数据写入excel表格的具体代码,供大家参考,具体内容如下 安装: xlsxwriter第三方库 code: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
本文向大家介绍C#读写EXCEL单元格的问题实现,包括了C#读写EXCEL单元格的问题实现的使用技巧和注意事项,需要的朋友参考一下 最近, 我在用C#开发一个EXCEL Add-In的时候,发现了一些害人不浅的坑,特来总结列举如下: 这里我读写EXCEL引用的是using Excel = Microsoft.Office.Interop.Excel; 问题一、如何判断一个单元格去除首尾空格后是不