
thinkphp 抓取网站的内容并且保存到本地的实例详解

thinkphp 抓取网站的内容并且保存到本地的实例详解
我需要写这么一个例子,到电子课本网下载一本电子书。
电子课本网的电子书,是把书的每一页当成一个图片,然后一本书就是有很多张图片,我需要批量的进行下载图片操作。
下面是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
我这里是以人教版地理七年级地理上册为例子 http://www.dzkbw.com/books/rjb/dili/xc7s/001.htm
网页是从001.htm开始,然后数字一直加
每个网页里面都有一张图,就是对应课本的内容,以图片的形式展示课本内容
我的代码是做了一个循环,从第一页开始抓,一直抓到找不到网页里的图片为止
抓到网页的内容后,把网页里面的图片抓取到本地服务器
抓取后的实际效果:
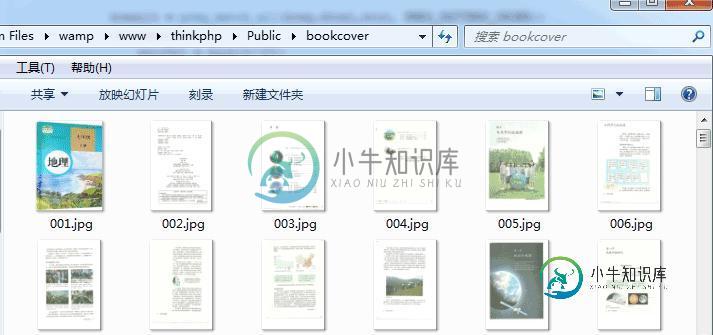
以上就是thinkphp 抓取网站的内容并且保存到本地的实例详解,如有疑问请留言或者到本站社区交流讨论,感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
-
本文向大家介绍python抓取网页中图片并保存到本地,包括了python抓取网页中图片并保存到本地的使用技巧和注意事项,需要的朋友参考一下 在上篇文章给大家分享PHP源码批量抓取远程网页图片并保存到本地的实现方法,感兴趣的朋友可以点击了解详情。 通过Python抓取指定Url中的图片保存至本地 以上代码是小编给大家介绍的python抓取网页中图片并保存到本地的全部内容,希望大家喜欢。
-
问题内容: 我需要从此网站Link中抓取新闻公告。公告似乎是动态生成的。它们不会出现在源代码中。我通常使用机械化,但是我认为它不会起作用。我该怎么办?我可以使用python或perl。 问题答案: 礼貌的选择是询问网站所有者是否具有允许您访问其新闻报道的API。 不太礼貌的选择是跟踪页面加载时发生的HTTP事务,并确定哪一个是AJAX调用,该调用会提取数据。 看起来就是这个。但是看起来它可能包含会
-
本文向大家介绍python抓取网站的图片并下载到本地的方法,包括了python抓取网站的图片并下载到本地的方法的使用技巧和注意事项,需要的朋友参考一下 实例如下所示: 以上这篇python抓取网站的图片并下载到本地的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
本文向大家介绍python爬取w3shcool的JQuery课程并且保存到本地,包括了python爬取w3shcool的JQuery课程并且保存到本地的使用技巧和注意事项,需要的朋友参考一下 最近在忙于找工作,闲暇之余,也找点爬虫项目练练手,写写代码,知道自己是个菜鸟,但是要多加练习,书山有路勤为径。各位爷有测试坑可以给我介绍个啊,自动化,功能,接口都可以做。 首先呢,我们明确需求,很多同学呢,有
-
我面临的问题很简单。如果我试图从一个网站获取一些数据,有两个同名的类。但是它们都包含一个具有不同信息的表。我所拥有的代码只向我输出第一个类的内容。它看起来像这样: 如何让代码输出两个表的内容或仅输出第二个表的内容?提前感谢您的回答!
-
问题内容: 因此,我正在使用python和beautifulsoup4(我不受其约束)来抓取网站。问题是当我使用urlib抓取页面的html时,它不是整个页面,因为其中一些是通过javascript生成的。有什么办法可以解决这个问题? 问题答案: 基本上有两个主要选项可以继续: 使用浏览器开发人员工具,查看哪些ajax请求将加载页面并在脚本中模拟它们,您可能需要使用json模块将响应json字符串