
90分钟实现一门编程语言(极简解释器教程)

本文介绍了如何使用 C# 实现一个简化 Scheme——iScheme 及其解释器。
如果你对下面的内容感兴趣:
- 实现基本的词法分析,语法分析并生成抽象语法树。
- 实现嵌套作用域和函数调用。
- 解释器的基本原理。
- 以及一些 C# 编程技巧。
那么请继续阅读。
如果你对以下内容感兴趣:
- 高级的词法/语法分析技术。
- 类型推导/分析。
- 目标代码优化。
本文则过于初级,你可以跳过本文,但欢迎指出本文的错误 :-)
代码样例
public static int Add(int a, int b) {
return a + b;
}
>> Add(3, 4)
>> 7
>> Add(5, 5)
>> 10
这段代码定义了 Add 函数,接下来的 >> 符号表示对 Add(3, 4) 进行求值,再下一行的 >> 7 表示上一行的求值结果,不同的求值用换行分开。可以把这里的 >> 理解成控制台提示符(即Terminal中的PS)。
什么是解释器
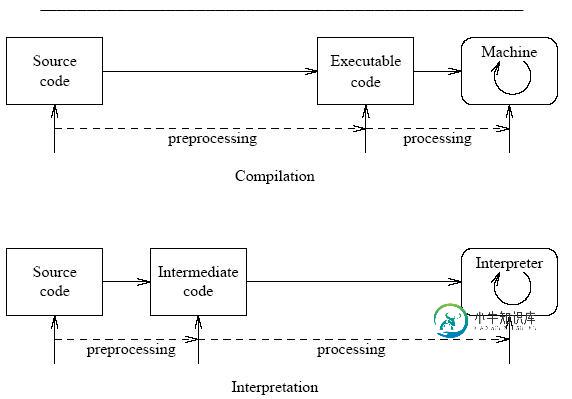
解释器(Interpreter)是一种程序,能够读入程序并直接输出结果,如上图。相对于编译器(Compiler),解释器并不会生成目标机器代码,而是直接运行源程序,简单来说:
解释器是运行程序的程序。
计算器就是一个典型的解释器,我们把数学公式(源程序)给它,它通过运行它内部的”解释器”给我们答案。

iScheme 编程语言
iScheme 是什么?
- Scheme 语言的一个极简子集。
- 虽然小,但变量,算术|比较|逻辑运算,列表,函数和递归这些编程语言元素一应俱全。
- 非常非常慢——可以说它只是为演示本文的概念而存在。
OK,那么 Scheme 是什么?
- 一种函数式程序设计语言。
- 一种 Lisp 方言。
- 麻省理工学院程序设计入门课程使用的语言(参见 MIT 6.001 和 计算机程序的构造与解释)。

使用 波兰表达式(Polish Notation)。
更多的介绍参见 [Scheme编程语言]。
以计算阶乘为例:
C#版阶乘
public static int Factorial(int n) {
if (n == 1) {
return 1;
} else {
return n * Factorial(n - 1);
}
}
iScheme版阶乘
(def factorial (lambda (n) (
if (= n 1)
1
(* n (factorial (- n 1))))))
数值类型
由于 iScheme 只是一个用于演示的语言,所以目前只提供对整数的支持。iScheme 使用 C# 的 Int64 类型作为其内部的数值表示方法。
定义变量
iScheme使用`def`关键字定义变量
>> (def a 3) >> 3 >> a >> 3
算术|逻辑|比较操作
与常见的编程语言(C#, Java, C++, C)不同,Scheme 使用 波兰表达式,即前缀表示法。例如:
C#中的算术|逻辑|比较操作
// Arithmetic ops a + b * c a / (b + c + d) // Logical ops (cond1 && cond2) || cond3 // Comparing ops a == b 1 < a && a < 3
对应的iScheme代码
; Arithmetic ops (+ a (* b c)) (/ a (+ b c d)) ; Logical ops (or (and cond1 cond2) cond3) ; Comparing ops (= a b) (< 1 a 3)
需要注意的几点:
iScheme 中的操作符可以接受不止两个参数——这在一定程度上控制了括号的数量。
iScheme 逻辑操作使用 and , or 和 not 代替了常见的 && , || 和 ! ——这在一定程度上增强了程序的可读性。
顺序语句
iScheme使用 begin 关键字标识顺序语句,并以最后一条语句的值作为返回结果。以求两个数的平均值为例:
C#的顺序语句
int a = 3; int b = 5; int c = (a + b) / 2;
iScheme的顺序语句
(def c (begin (def a 3) (def b 5) (/ (+ a b) 2)))
控制流操作
iScheme 中的控制流操作只包含 if 。
if语句示例
>> (define a (if (> 3 2) 1 2)) >> 1 >> a >> 1
列表类型
iScheme 使用 list 关键字定义列表,并提供 first 关键字获取列表的第一个元素;提供 rest 关键字获取列表除第一个元素外的元素。
iScheme的列表示例
>> (define alist (list 1 2 3 4)) >> (list 1 2 3 4) >> (first alist) >> 1 >> (rest alist) >> (2 3 4)
定义函数
iScheme 使用 func 关键字定义函数:
iScheme的函数定义
(def square (func (x) (* x x))) (def sum_square (func (a b) (+ (square a) (square b))))
对应的C#代码
public static int Square (int x) {
return x * x;
}
public static int SumSquare(int a, int b) {
return Square(a) + Square(b);
}
递归
由于 iScheme 中没有 for 或 while 这种命令式语言(Imperative Programming Language)的循环结构,递归成了重复操作的唯一选择。
以计算最大公约数为例:
iScheme计算最大公约数
(def gcd (func (a b)
(if (= b 0)
a
(func (b (% a b))))))
对应的C#代码
public static int GCD (int a, int b) {
if (b == 0) {
return a;
} else {
return GCD(b, a % b);
}
}
高阶函数
和 Scheme 一样,函数在 iScheme 中是头等对象,这意味着:
- 可以定义一个变量为函数。
- 函数可以接受一个函数作为参数。
- 函数返回一个函数。
iScheme 的高阶函数示例
; Defines a multiply function.
(def mul (func (a b) (* a b)))
; Defines a list map function.
(def map (func (f alist)
(if (empty? alist)
(list )
(append (list (f (first alist))) (map f (rest alist)))
)))
; Doubles a list using map and mul.
>> (map (mul 2) (list 1 2 3))
>> (list 2 4 6)
小结
对 iScheme 的介绍就到这里——事实上这就是 iScheme 的所有元素,会不会太简单了? -_-
接下来进入正题——从头开始构造 iScheme 的解释程序。
解释器构造
iScheme 解释器主要分为两部分,解析(Parse)和求值(Evaluation):
1、解析(Parse):解析源程序,并生成解释器可以理解的中间(Intermediate)结构。这部分包含词法分析,语法分析,语义分析,生成语法树。
2、求值(Evaluation):执行解析阶段得到的中介结构然后得到运行结果。这部分包含作用域,类型系统设计和语法树遍历。
词法分析
词法分析负责把源程序解析成一个个词法单元(Lex),以便之后的处理。
iScheme 的词法分析极其简单——由于 iScheme 的词法元素只包含括号,空白,数字和变量名,因此C#自带的 String#Split 就足够。
iScheme的词法分析及测试
public static String[] Tokenize(String text) {
String[] tokens = text.Replace("(", " ( ").Replace(")", " ) ").Split(" \t\r\n".ToArray(), StringSplitOptions.RemoveEmptyEntries);
return tokens;
}
// Extends String.Join for a smooth API.
public static String Join(this String separator, IEnumerable<Object> values) {
return String.Join(separator, values);
}
// Displays the lexes in a readable form.
public static String PrettyPrint(String[] lexes) {
return "[" + ", ".Join(lexes.Select(s => "'" + s + "'") + "]";
}
// Some tests
>> PrettyPrint(Tokenize("a"))
>> ['a']
>> PrettyPrint(Tokenize("(def a 3)"))
>> ['(', 'def', 'a', '3', ')']
>> PrettyPrint(Tokenize("(begin (def a 3) (* a a))"))
>> ['begin', '(', 'def', 'a', '3', ')', '(', '*', 'a', 'a', ')', ')']
注意
- 个人不喜欢 String.Join 这个静态方法,所以这里使用C#的扩展方法(Extension Methods)对String类型做了一个扩展。
- 相对于LINQ Syntax,我个人更喜欢LINQ Extension Methods,接下来的代码也都会是这种风格。
- 不要以为词法分析都是这么离谱般简单!vczh的词法分析教程给出了一个完整编程语言的词法分析教程。
语法树生成
得到了词素之后,接下来就是进行语法分析。不过由于 Lisp 类语言的程序即是语法树,所以语法分析可以直接跳过。
以下面的程序为例:
程序即语法树
;
(def x (if (> a 1) a 1))
; 换一个角度看的话:
(
def
x
(
if
(
>
a
1
)
a
1
)
)
更加直观的图片:
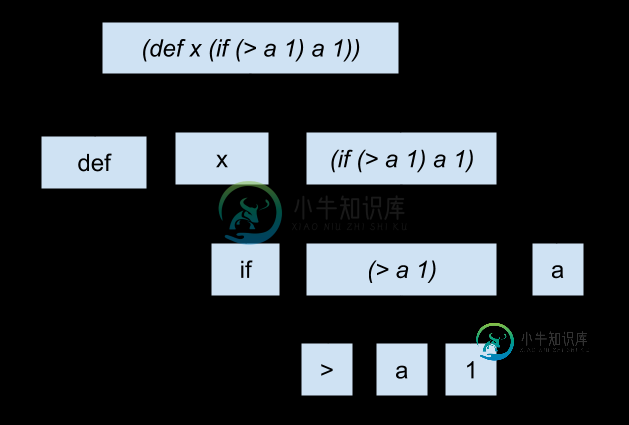
这使得抽象语法树(Abstract Syntax Tree)的构建变得极其简单(无需考虑操作符优先级等问题),我们使用 SExpression 类型定义 iScheme 的语法树(事实上S Expression也是Lisp表达式的名字)。
抽象语法树的定义
public class SExpression {
public String Value { get; private set; }
public List<SExpression> Children { get; private set; }
public SExpression Parent { get; private set; }
public SExpression(String value, SExpression parent) {
this.Value = value;
this.Children = new List<SExpression>();
this.Parent = parent;
}
public override String ToString() {
if (this.Value == "(") {
return "(" + " ".Join(Children) + ")";
} else {
return this.Value;
}
}
}
然后用下面的步骤构建语法树:
- 碰到左括号,创建一个新的节点到当前节点( current ),然后重设当前节点。
- 碰到右括号,回退到当前节点的父节点。
- 否则把为当前词素创建节点,添加到当前节点中。
抽象语法树的构建过程
public static SExpression ParseAsIScheme(this String code) {
SExpression program = new SExpression(value: "", parent: null);
SExpression current = program;
foreach (var lex in Tokenize(code)) {
if (lex == "(") {
SExpression newNode = new SExpression(value: "(", parent: current);
current.Children.Add(newNode);
current = newNode;
} else if (lex == ")") {
current = current.Parent;
} else {
current.Children.Add(new SExpression(value: lex, parent: current));
}
}
return program.Children[0];
}
注意
- 使用 自动属性(Auto Property),从而避免重复编写样版代码(Boilerplate Code)。
- 使用 命名参数(Named Parameters)提高代码可读性: new SExpression(value: "", parent: null) 比 new SExpression("", null) 可读。
- 使用 扩展方法 提高代码流畅性: code.Tokenize().ParseAsIScheme 比 ParseAsIScheme(Tokenize(code)) 流畅。
- 大多数编程语言的语法分析不会这么简单!如果打算实现一个类似C#的编程语言,你需要更强大的语法分析技术:
- 如果打算手写语法分析器,可以参考 LL(k), Precedence Climbing 和Top Down Operator Precedence。
- 如果打算生成语法分析器,可以参考 ANTLR 或 Bison。
作用域
作用域决定程序的运行环境。iScheme使用嵌套作用域。
以下面的程序为例
>> (def x 1) >> 1 >> (def y (begin (def x 2) (* x x))) >> 4 >> x >> 1

利用C#提供的 Dictionary<TKey, TValue> 类型,我们可以很容易的实现 iScheme 的作用域 SScope :
iScheme的作用域实现
public class SScope {
public SScope Parent { get; private set; }
private Dictionary<String, SObject> variableTable;
public SScope(SScope parent) {
this.Parent = parent;
this.variableTable = new Dictionary<String, SObject>();
}
public SObject Find(String name) {
SScope current = this;
while (current != null) {
if (current.variableTable.ContainsKey(name)) {
return current.variableTable[name];
}
current = current.Parent;
}
throw new Exception(name + " is not defined.");
}
public SObject Define(String name, SObject value) {
this.variableTable.Add(name, value);
return value;
}
}
类型实现
iScheme 的类型系统极其简单——只有数值,Bool,列表和函数,考虑到他们都是 iScheme 里面的值对象(Value Object),为了便于对它们进行统一处理,这里为它们设置一个统一的父类型 SObject :
public class SObject { }
数值类型
iScheme 的数值类型只是对 .Net 中 Int64 (即 C# 里的 long )的简单封装:
public class SNumber : SObject {
private readonly Int64 value;
public SNumber(Int64 value) {
this.value = value;
}
public override String ToString() {
return this.value.ToString();
}
public static implicit operator Int64(SNumber number) {
return number.value;
}
public static implicit operator SNumber(Int64 value) {
return new SNumber(value);
}
}
注意这里使用了 C# 的隐式操作符重载,这使得我们可以:
SNumber foo = 30; SNumber bar = 40; SNumber foobar = foo * bar;
而不必:
SNumber foo = new SNumber(value: 30); SNumber bar = new SNumber(value: 40); SNumber foobar = new SNumber(value: foo.Value * bar.Value);
为了方便,这里也为 SObject 增加了隐式操作符重载(尽管 Int64 可以被转换为 SNumber 且 SNumber 继承自 SObject ,但 .Net 无法直接把 Int64 转化为 SObject ):
public class SObject {
...
public static implicit operator SObject(Int64 value) {
return (SNumber)value;
}
}
Bool类型
由于 Bool 类型只有 True 和 False,所以使用静态对象就足矣。
public class SBool : SObject {
public static readonly SBool False = new SBool();
public static readonly SBool True = new SBool();
public override String ToString() {
return ((Boolean)this).ToString();
}
public static implicit operator Boolean(SBool value) {
return value == SBool.True;
}
public static implicit operator SBool(Boolean value) {
return value ? True : False;
}
}
这里同样使用了 C# 的 隐式操作符重载,这使得我们可以:
SBool foo = a > 1;
if (foo) {
// Do something...
}
而不用
SBool foo = a > 1 ? SBool.True: SBool.False;
if (foo == SBool.True) {
// Do something...
}
同样,为 SObject 增加 隐式操作符重载:
public class SObject {
...
public static implicit operator SObject(Boolean value) {
return (SBool)value;
}
}
列表类型
iScheme使用.Net中的 IEnumberable<T> 实现列表类型 SList :
public class SList : SObject, IEnumerable<SObject> {
private readonly IEnumerable<SObject> values;
public SList(IEnumerable<SObject> values) {
this.values = values;
}
public override String ToString() {
return "(list " + " ".Join(this.values) + ")";
}
public IEnumerator<SObject> GetEnumerator() {
return this.values.GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator() {
return this.values.GetEnumerator();
}
}
实现 IEnumerable<SObject> 后,就可以直接使用LINQ的一系列扩展方法,十分方便。
函数类型
iScheme 的函数类型( SFunction )由三部分组成:
- 函数体:即对应的 SExpression 。
- 参数列表。
- 作用域:函数拥有自己的作用域
SFunction的实现
public class SFunction : SObject {
public SExpression Body { get; private set; }
public String[] Parameters { get; private set; }
public SScope Scope { get; private set; }
public Boolean IsPartial {
get {
return this.ComputeFilledParameters().Length.InBetween(1, this.Parameters.Length);
}
}
public SFunction(SExpression body, String[] parameters, SScope scope) {
this.Body = body;
this.Parameters = parameters;
this.Scope = scope;
}
public SObject Evaluate() {
String[] filledParameters = this.ComputeFilledParameters();
if (filledParameters.Length < Parameters.Length) {
return this;
} else {
return this.Body.Evaluate(this.Scope);
}
}
public override String ToString() {
return String.Format("(func ({0}) {1})",
" ".Join(this.Parameters.Select(p => {
SObject value = null;
if ((value = this.Scope.FindInTop(p)) != null) {
return p + ":" + value;
}
return p;
})), this.Body);
}
private String[] ComputeFilledParameters() {
return this.Parameters.Where(p => Scope.FindInTop(p) != null).ToArray();
}
}
需要注意的几点
iScheme 支持部分求值(Partial Evaluation),这意味着:
部分求值
>> (def mul (func (a b) (* a b))) >> (func (a b) (* a b)) >> (mul 3 4) >> 12 >> (mul 3) >> (func (a:3 b) (* a b)) >> ((mul 3) 4) >> 12
也就是说,当 SFunction 的实际参数(Argument)数量小于其形式参数(Parameter)的数量时,它依然是一个函数,无法被求值。
这个功能有什么用呢?生成高阶函数。有了部分求值,我们就可以使用
(def mul (func (a b) (* a b))) (def mul3 (mul 3)) >> (mul3 3) >> 9
而不用专门定义一个生成函数:
(def times (func (n) (func (n x) (* n x)) ) ) (def mul3 (times 3)) >> (mul3 3) >> 9
SFunction#ToString 可以将其自身还原为源代码——从而大大简化了 iScheme 的理解和测试。
内置操作
iScheme 的内置操作有四种:算术|逻辑|比较|列表操作。
我选择了表达力(Expressiveness)强的 lambda 方法表来定义内置操作:
首先在 SScope 中添加静态字段 builtinFunctions ,以及对应的访问属性 BuiltinFunctions 和操作方法 BuildIn 。
public class SScope {
private static Dictionary<String, Func<SExpression[], SScope, SObject>> builtinFunctions =
new Dictionary<String, Func<SExpression[], SScope, SObject>>();
public static Dictionary<String, Func<SExpression[], SScope, SObject>> BuiltinFunctions {
get { return builtinFunctions; }
}
// Dirty HACK for fluent API.
public SScope BuildIn(String name, Func<SExpression[], SScope, SObject> builtinFuntion) {
SScope.builtinFunctions.Add(name, builtinFuntion);
return this;
}
}
注意:
- Func<T1, T2, TRESULT> 是 C# 提供的委托类型,表示一个接受 T1 和 T2 ,返回 TRESULT
- 这里有一个小 HACK,使用实例方法(Instance Method)修改静态成员(Static Member),从而实现一套流畅的 API(参见Fluent Interface)。
接下来就可以这样定义内置操作:
new SScope(parent: null)
.BuildIn("+", addMethod)
.BuildIn("-", subMethod)
.BuildIn("*", mulMethod)
.BuildIn("/", divMethod);
一目了然。
断言(Assertion)扩展
为了便于进行断言,我对 Boolean 类型做了一点点扩展。
public static void OrThrows(this Boolean condition, String message = null) {
if (!condition) { throw new Exception(message ?? "WTF"); }
}
从而可以写出流畅的断言:
(a < 3).OrThrows("Value must be less than 3.");
而不用
if (a < 3) {
throw new Exception("Value must be less than 3.");
}
算术操作
iScheme 算术操作包含 + - * / % 五个操作,它们仅应用于数值类型(也就是 SNumber )。
从加减法开始:
.BuildIn("+", (args, scope) => {
var numbers = args.Select(obj => obj.Evaluate(scope)).Cast<SNumber>();
return numbers.Sum(n => n);
})
.BuildIn("-", (args, scope) => {
var numbers = args.Select(obj => obj.Evaluate(scope)).Cast<SNumber>().ToArray();
Int64 firstValue = numbers[0];
if (numbers.Length == 1) {
return -firstValue;
}
return firstValue - numbers.Skip(1).Sum(s => s);
})
注意到这里有一段重复逻辑负责转型求值(Cast then Evaluation),考虑到接下来还有不少地方要用这个逻辑,我把这段逻辑抽象成扩展方法:
public static IEnumerable<T> Evaluate<T>(this IEnumerable<SExpression> expressions, SScope scope)
where T : SObject {
return expressions.Evaluate(scope).Cast<T>();
}
public static IEnumerable<SObject> Evaluate(this IEnumerable<SExpression> expressions, SScope scope) {
return expressions.Select(exp => exp.Evaluate(scope));
}
然后加减法就可以如此定义:
.BuildIn("+", (args, scope) => (args.Evaluate<SNumber>(scope).Sum(s => s)))
.BuildIn("-", (args, scope) => {
var numbers = args.Evaluate<SNumber>(scope).ToArray();
Int64 firstValue = numbers[0];
if (numbers.Length == 1) {
return -firstValue;
}
return firstValue - numbers.Skip(1).Sum(s => s);
})
乘法,除法和求模定义如下:
.BuildIn("*", (args, scope) => args.Evaluate<SNumber>(scope).Aggregate((a, b) => a * b))
.BuildIn("/", (args, scope) => {
var numbers = args.Evaluate<SNumber>(scope).ToArray();
Int64 firstValue = numbers[0];
return firstValue / numbers.Skip(1).Aggregate((a, b) => a * b);
})
.BuildIn("%", (args, scope) => {
(args.Length == 2).OrThrows("Parameters count in mod should be 2");
var numbers = args.Evaluate<SNumber>(scope).ToArray();
return numbers[0] % numbers[1];
})
逻辑操作
iScheme 逻辑操作包括 and , or 和 not ,即与,或和非。
需要注意的是 iScheme 逻辑操作是 短路求值(Short-circuit evaluation),也就是说:
- (and condA condB) ,如果 condA 为假,那么整个表达式为假,无需对 condB 求值。
- (or condA condB) ,如果 condA 为真,那么整个表达式为真,无需对 condB 求值。
此外和 + - * / 一样, and 和 or 也可以接收任意数量的参数。
需求明确了接下来就是实现,iScheme 的逻辑操作实现如下:
.BuildIn("and", (args, scope) => {
(args.Length > 0).OrThrows();
return !args.Any(arg => !(SBool)arg.Evaluate(scope));
})
.BuildIn("or", (args, scope) => {
(args.Length > 0).OrThrows();
return args.Any(arg => (SBool)arg.Evaluate(scope));
})
.BuildIn("not", (args, scope) => {
(args.Length == 1).OrThrows();
return args[0].Evaluate(scope);
})
比较操作
iScheme 的比较操作包括 = < > >= <= ,需要注意下面几点:
- = 是比较操作而非赋值操作。
-
同算术操作一样,它们应用于数值类型,并支持任意数量的参数。
= 的实现如下:
.BuildIn("=", (args, scope) => {
(args.Length > 1).OrThrows("Must have more than 1 argument in relation operation.");
SNumber current = (SNumber)args[0].Evaluate(scope);
foreach (var arg in args.Skip(1)) {
SNumber next = (SNumber)arg.Evaluate(scope);
if (current == next) {
current = next;
} else {
return false;
}
}
return true;
})
可以预见所有的比较操作都将使用这段逻辑,因此把这段比较逻辑抽象成一个扩展方法:
public static SBool ChainRelation(this SExpression[] expressions, SScope scope, Func<SNumber, SNumber, Boolean> relation) {
(expressions.Length > 1).OrThrows("Must have more than 1 parameter in relation operation.");
SNumber current = (SNumber)expressions[0].Evaluate(scope);
foreach (var obj in expressions.Skip(1)) {
SNumber next = (SNumber)obj.Evaluate(scope);
if (relation(current, next)) {
current = next;
} else {
return SBool.False;
}
}
return SBool.True;
}
接下来就可以很方便的定义比较操作:
.BuildIn("=", (args, scope) => args.ChainRelation(scope, (s1, s2) => (Int64)s1 == (Int64)s2))
.BuildIn(">", (args, scope) => args.ChainRelation(scope, (s1, s2) => s1 > s2))
.BuildIn("<", (args, scope) => args.ChainRelation(scope, (s1, s2) => s1 < s2))
.BuildIn(">=", (args, scope) => args.ChainRelation(scope, (s1, s2) => s1 >= s2))
.BuildIn("<=", (args, scope) => args.ChainRelation(scope, (s1, s2) => s1 <= s2))
注意 = 操作的实现里面有 Int64 强制转型——因为我们没有重载 SNumber#Equals ,所以无法直接通过 == 来比较两个 SNumber 。
列表操作
iScheme 的列表操作包括 first , rest , empty? 和 append ,分别用来取列表的第一个元素,除第一个以外的部分,判断列表是否为空和拼接列表。
first 和 rest 操作如下:
.BuildIn("first", (args, scope) => {
SList list = null;
(args.Length == 1 && (list = (args[0].Evaluate(scope) as SList)) != null).OrThrows("<first> must apply to a list.");
return list.First();
})
.BuildIn("rest", (args, scope) => {
SList list = null;
(args.Length == 1 && (list = (args[0].Evaluate(scope) as SList)) != null).OrThrows("<rest> must apply to a list.");
return new SList(list.Skip(1));
})
又发现相当的重复逻辑——判断参数是否是一个合法的列表,重复代码很邪恶,所以这里把这段逻辑抽象为扩展方法:
public static SList RetrieveSList(this SExpression[] expressions, SScope scope, String operationName) {
SList list = null;
(expressions.Length == 1 && (list = (expressions[0].Evaluate(scope) as SList)) != null)
.OrThrows("<" + operationName + "> must apply to a list");
return list;
}
有了这个扩展方法,接下来的列表操作就很容易实现:
.BuildIn("first", (args, scope) => args.RetrieveSList(scope, "first").First())
.BuildIn("rest", (args, scope) => new SList(args.RetrieveSList(scope, "rest").Skip(1)))
.BuildIn("append", (args, scope) => {
SList list0 = null, list1 = null;
(args.Length == 2
&& (list0 = (args[0].Evaluate(scope) as SList)) != null
&& (list1 = (args[1].Evaluate(scope) as SList)) != null).OrThrows("Input must be two lists");
return new SList(list0.Concat(list1));
})
.BuildIn("empty?", (args, scope) => args.RetrieveSList(scope, "empty?").Count() == 0)
测试
iScheme 的内置操作完成之后,就可以测试下初步成果了。
首先添加基于控制台的分析/求值(Parse/Evaluation)循环:
public static void KeepInterpretingInConsole(this SScope scope, Func<String, SScope, SObject> evaluate) {
while (true) {
try {
Console.ForegroundColor = ConsoleColor.Gray;
Console.Write(">> ");
String code;
if (!String.IsNullOrWhiteSpace(code = Console.ReadLine())) {
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine(">> " + evaluate(code, scope));
}
} catch (Exception ex) {
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine(">> " + ex.Message);
}
}
}
然后在 SExpression#Evaluate 中补充调用代码:
public override SObject Evaluate(SScope scope) {
if (this.Children.Count == 0) {
Int64 number;
if (Int64.TryParse(this.Value, out number)) {
return number;
}
} else {
SExpression first = this.Children[0];
if (SScope.BuiltinFunctions.ContainsKey(first.Value)) {
var arguments = this.Children.Skip(1).Select(node => node.Evaluate(scope)).ToArray();
return SScope.BuiltinFunctions[first.Value](arguments, scope);
}
}
throw new Exception("THIS IS JUST TEMPORARY!");
}
最后在 Main 中调用该解释/求值循环:
static void Main(String[] cmdArgs) {
new SScope(parent: null)
.BuildIn("+", (args, scope) => (args.Evaluate<SNumber>(scope).Sum(s => s)))
// 省略若干内置函数
.BuildIn("empty?", (args, scope) => args.RetrieveSList("empty?").Count() == 0)
.KeepInterpretingInConsole((code, scope) => code.ParseAsScheme().Evaluate(scope));
}
运行程序,输入一些简单的表达式:
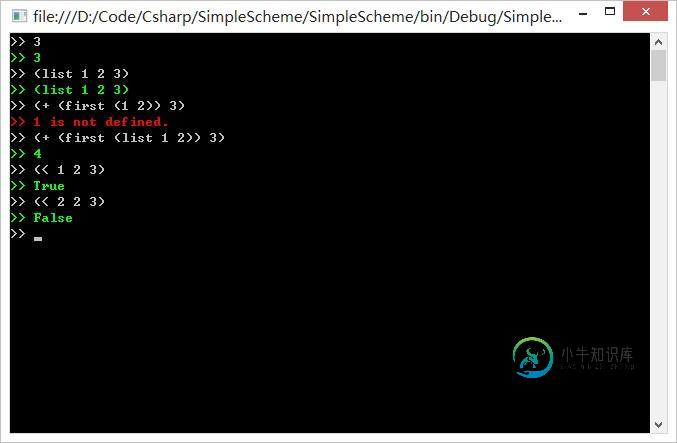
看样子还不错 :-)
接下来开始实现iScheme的执行(Evaluation)逻辑。
执行逻辑
iScheme 的执行就是把语句(SExpression)在作用域(SScope)转化成对象(SObject)并对作用域(SScope)产生作用的过程,如下图所示。
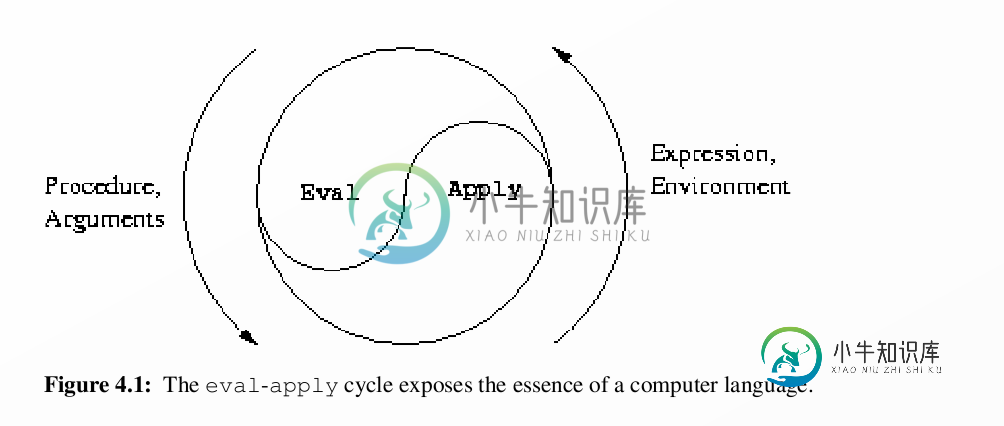
iScheme的执行逻辑就在 SExpression#Evaluate 里面:
public class SExpression {
// ...
public override SObject Evaluate(SScope scope) {
// TODO: Todo your ass.
}
}
首先明确输入和输出:
- 处理字面量(Literals): 3 ;和具名量(Named Values): x
- 处理 if :(if (< a 3) 3 a)
- 处理 def :(def pi 3.14)
- 处理 begin :(begin (def a 3) (* a a))
- 处理 func :(func (x) (* x x))
- 处理内置函数调用:(+ 1 2 3 (first (list 1 2)))
- 处理自定义函数调用:(map (func (x) (* x x)) (list 1 2 3))
此外,情况1和2中的 SExpression 没有子节点,可以直接读取其 Value 进行求值,余下的情况需要读取其 Children 进行求值。
首先处理没有子节点的情况:
处理字面量和具名量
if (this.Children.Count == 0) {
Int64 number;
if (Int64.TryParse(this.Value, out number)) {
return number;
} else {
return scope.Find(this.Value);
}
}
接下来处理带有子节点的情况:
首先获得当前节点的第一个节点:
SExpression first = this.Children[0];
然后根据该节点的 Value 决定下一步操作:
处理 if
if 语句的处理方法很直接——根据判断条件(condition)的值判断执行哪条语句即可:
if (first.Value == "if") {
SBool condition = (SBool)(this.Children[1].Evaluate(scope));
return condition ? this.Children[2].Evaluate(scope) : this.Children[3].Evaluate(scope);
}
处理 def
直接定义即可:
else if (first.Value == "def") {
return scope.Define(this.Children[1].Value, this.Children[2].Evaluate(new SScope(scope)));
}
处理 begin
遍历语句,然后返回最后一条语句的值:
else if (first.Value == "begin") {
SObject result = null;
foreach (SExpression statement in this.Children.Skip(1)) {
result = statement.Evaluate(scope);
}
return result;
}
处理 func
利用 SExpression 构建 SFunction ,然后返回:
else if (first.Value == "func") {
SExpression body = this.Children[2];
String[] parameters = this.Children[1].Children.Select(exp => exp.Value).ToArray();
SScope newScope = new SScope(scope);
return new SFunction(body, parameters, newScope);
}
处理 list
首先把 list 里的元素依次求值,然后创建 SList :
else if (first.Value == "list") {
return new SList(this.Children.Skip(1).Select(exp => exp.Evaluate(scope)));
}
处理内置操作
首先得到参数的表达式,然后调用对应的内置函数:
else if (SScope.BuiltinFunctions.ContainsKey(first.Value)) {
var arguments = this.Children.Skip(1).ToArray();
return SScope.BuiltinFunctions[first.Value](arguments, scope);
}
处理自定义函数调用
自定义函数调用有两种情况:
- 非具名函数调用:((func (x) (* x x)) 3)
- 具名函数调用:(square 3)
调用自定义函数时应使用新的作用域,所以为 SFunction 增加 Update 方法:
public SFunction Update(SObject[] arguments) {
var existingArguments = this.Parameters.Select(p => this.Scope.FindInTop(p)).Where(obj => obj != null);
var newArguments = existingArguments.Concat(arguments).ToArray();
SScope newScope = this.Scope.Parent.SpawnScopeWith(this.Parameters, newArguments);
return new SFunction(this.Body, this.Parameters, newScope);
}
为了便于创建自定义作用域,并判断函数的参数是否被赋值,为 SScope 增加 SpawnScopeWith 和 FindInTop 方法:
public SScope SpawnScopeWith(String[] names, SObject[] values) {
(names.Length >= values.Length).OrThrows("Too many arguments.");
SScope scope = new SScope(this);
for (Int32 i = 0; i < values.Length; i++) {
scope.variableTable.Add(names[i], values[i]);
}
return scope;
}
public SObject FindInTop(String name) {
if (variableTable.ContainsKey(name)) {
return variableTable[name];
}
return null;
}
下面是函数调用的实现:
else {
SFunction function = first.Value == "(" ? (SFunction)first.Evaluate(scope) : (SFunction)scope.Find(first.Value);
var arguments = this.Children.Skip(1).Select(s => s.Evaluate(scope)).ToArray();
return function.Update(arguments).Evaluate();
}
完整的求值代码
综上所述,求值代码如下
public SObject Evaluate(SScope scope) {
if (this.Children.Count == 0) {
Int64 number;
if (Int64.TryParse(this.Value, out number)) {
return number;
} else {
return scope.Find(this.Value);
}
} else {
SExpression first = this.Children[0];
if (first.Value == "if") {
SBool condition = (SBool)(this.Children[1].Evaluate(scope));
return condition ? this.Children[2].Evaluate(scope) : this.Children[3].Evaluate(scope);
} else if (first.Value == "def") {
return scope.Define(this.Children[1].Value, this.Children[2].Evaluate(new SScope(scope)));
} else if (first.Value == "begin") {
SObject result = null;
foreach (SExpression statement in this.Children.Skip(1)) {
result = statement.Evaluate(scope);
}
return result;
} else if (first.Value == "func") {
SExpression body = this.Children[2];
String[] parameters = this.Children[1].Children.Select(exp => exp.Value).ToArray();
SScope newScope = new SScope(scope);
return new SFunction(body, parameters, newScope);
} else if (first.Value == "list") {
return new SList(this.Children.Skip(1).Select(exp => exp.Evaluate(scope)));
} else if (SScope.BuiltinFunctions.ContainsKey(first.Value)) {
var arguments = this.Children.Skip(1).ToArray();
return SScope.BuiltinFunctions[first.Value](arguments, scope);
} else {
SFunction function = first.Value == "(" ? (SFunction)first.Evaluate(scope) : (SFunction)scope.Find(first.Value);
var arguments = this.Children.Skip(1).Select(s => s.Evaluate(scope)).ToArray();
return function.Update(arguments).Evaluate();
}
}
}
去除尾递归
到了这里 iScheme 解释器就算完成了。但仔细观察求值过程还是有一个很大的问题,尾递归调用:
- 处理 if 的尾递归调用。
- 处理函数调用中的尾递归调用。
Alex Stepanov 曾在 Elements of Programming 中介绍了一种将严格尾递归调用(Strict tail-recursive call)转化为迭代的方法,细节恕不赘述,以阶乘为例:
// Recursive factorial.
int fact (int n) {
if (n == 1)
return result;
return n * fact(n - 1);
}
// First tranform to tail recursive version.
int fact (int n, int result) {
if (n == 1)
return result;
else {
result *= n;
n -= 1;
return fact(n, result);// This is a strict tail-recursive call which can be omitted
}
}
// Then transform to iterative version.
int fact (int n, int result) {
while (true) {
if (n == 1)
return result;
else {
result *= n;
n -= 1;
}
}
}
应用这种方法到 SExpression#Evaluate ,得到转换后的版本:
public SObject Evaluate(SScope scope) {
SExpression current = this;
while (true) {
if (current.Children.Count == 0) {
Int64 number;
if (Int64.TryParse(current.Value, out number)) {
return number;
} else {
return scope.Find(current.Value);
}
} else {
SExpression first = current.Children[0];
if (first.Value == "if") {
SBool condition = (SBool)(current.Children[1].Evaluate(scope));
current = condition ? current.Children[2] : current.Children[3];
} else if (first.Value == "def") {
return scope.Define(current.Children[1].Value, current.Children[2].Evaluate(new SScope(scope)));
} else if (first.Value == "begin") {
SObject result = null;
foreach (SExpression statement in current.Children.Skip(1)) {
result = statement.Evaluate(scope);
}
return result;
} else if (first.Value == "func") {
SExpression body = current.Children[2];
String[] parameters = current.Children[1].Children.Select(exp => exp.Value).ToArray();
SScope newScope = new SScope(scope);
return new SFunction(body, parameters, newScope);
} else if (first.Value == "list") {
return new SList(current.Children.Skip(1).Select(exp => exp.Evaluate(scope)));
} else if (SScope.BuiltinFunctions.ContainsKey(first.Value)) {
var arguments = current.Children.Skip(1).ToArray();
return SScope.BuiltinFunctions[first.Value](arguments, scope);
} else {
SFunction function = first.Value == "(" ? (SFunction)first.Evaluate(scope) : (SFunction)scope.Find(first.Value);
var arguments = current.Children.Skip(1).Select(s => s.Evaluate(scope)).ToArray();
SFunction newFunction = function.Update(arguments);
if (newFunction.IsPartial) {
return newFunction.Evaluate();
} else {
current = newFunction.Body;
scope = newFunction.Scope;
}
}
}
}
}
一些演示
基本的运算
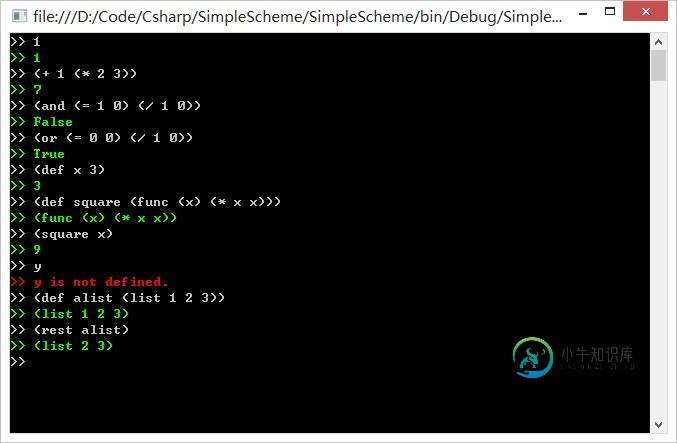
高阶函数
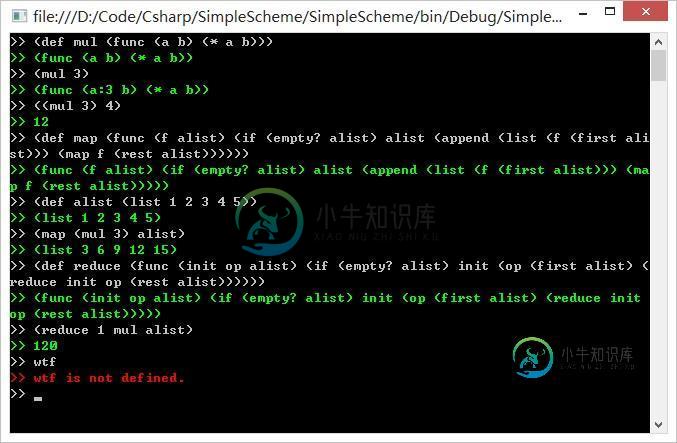
回顾
小结
除去注释(貌似没有注释-_-),iScheme 的解释器的实现代码一共 333 行——包括空行,括号等元素。
在这 300 余行代码里,实现了函数式编程语言的大部分功能:算术|逻辑|运算,嵌套作用域,顺序语句,控制语句,递归,高阶函数,部分求值。
与我两年之前实现的 Scheme 方言 Lucida相比,iScheme 除了没有字符串类型,其它功能和Lucida相同,而代码量只是前者的八分之一,编写时间是前者的十分之一(Lucida 用了两天,iScheme 用了一个半小时),可扩展性和易读性均秒杀前者。这说明了:
- 代码量不能说明问题。
- 不同开发者生产效率的差别会非常巨大。
- 这两年我还是学到了一点东西的。-_-
一些设计决策
使用扩展方法提高可读性
例如,通过定义 OrThrows
public static void OrThrows(this Boolean condition, String message = null) {
if (!condition) { throw new Exception(message ?? "WTF"); }
}
写出流畅的断言:
(a < 3).OrThrows("Value must be less than 3.");
声明式编程风格
以 Main 函数为例:
static void Main(String[] cmdArgs) {
new SScope(parent: null)
.BuildIn("+", (args, scope) => (args.Evaluate<SNumber>(scope).Sum(s => s)))
// Other build
.BuildIn("empty?", (args, scope) => args.RetrieveSList("empty?").Count() == 0)
.KeepInterpretingInConsole((code, scope) => code.ParseAsIScheme().Evaluate(scope));
}
非常直观,而且
- 如果需要添加新的操作,添加写一行 BuildIn 即可。
- 如果需要使用其它语法,替换解析函数 ParseAsIScheme 即可。
- 如果需要从文件读取代码,替换执行函数 KeepInterpretingInConsole 即可。
不足
当然iScheme还是有很多不足:
语言特性方面:
- 缺乏实用类型:没有 Double 和 String 这两个关键类型,更不用说复合类型(Compound Type)。
- 没有IO操作,更不要说网络通信。
- 效率低下:尽管去除尾递归挽回了一点效率,但iScheme的执行效率依然惨不忍睹。
- 错误信息:错误信息基本不可读,往往出错了都不知道从哪里找起。
- 不支持延续调用(Call with current continuation,即call/cc)。
- 没有并发。
- 各种bug:比如可以定义文本量,无法重载默认操作,空括号被识别等等。
设计实现方面:
- 使用了可变(Mutable)类型。
- 没有任何注释(因为觉得没有必要 -_-)。
- 糟糕的类型系统:Lisp类语言中的数据和程序可以不分彼此,而iScheme的实现中确把数据和程序分成了 SObject 和 SExpression ,现在我依然没有找到一个融合他们的好办法。
这些就留到以后慢慢处理了 -_-(TODO YOUR ASS)
延伸阅读
书籍
- Compilers: Priciples, Techniques and Tools Principles: http://www.amazon.co.uk/Compilers-Principles-Techniques-V-Aho/dp/1292024348/
- Language Implementation Patterns: http://www.amazon.co.uk/Language-Implementation-Patterns-Domain-Specific-Programming/dp/193435645X/
- *The Definitive ANTLR4 Reference: http://www.amazon.co.uk/Definitive-ANTLR-4-Reference/dp/1934356999/
- Engineering a compiler: http://www.amazon.co.uk/Engineering-Compiler-Keith-Cooper/dp/012088478X/
- Flex & Bison: http://www.amazon.co.uk/flex-bison-John-Levine/dp/0596155972/
- *Writing Compilers and Interpreters: http://www.amazon.co.uk/Writing-Compilers-Interpreters-Software-Engineering/dp/0470177071/
- Elements of Programming: http://www.amazon.co.uk/Elements-Programming-Alexander-Stepanov/dp/032163537X/
注:带*号的没有中译本。
文章
大多和编译前端相关,自己没时间也没能力研究后端。-_-
为什么编译技术很重要?看看 Steve Yegge(没错,就是被王垠黑过的 Google 高级技术工程师)是怎么说的(需要翻墙)。
http://steve-yegge.blogspot.co.uk/2007/06/rich-programmer-food.html
本文重点参考的 Peter Norvig 的两篇文章:
- How to write a lisp interpreter in Python: http://norvig.com/lispy.html
- An even better lisp interpreter in Python: http://norvig.com/lispy2.html
几种简单实用的语法分析技术:
- LL(k) Parsing:
- http://eli.thegreenplace.net/2008/09/26/recursive-descent-ll-and-predictive-parsers/
- http://eli.thegreenplace.net/2009/03/20/a-recursive-descent-parser-with-an-infix-expression-evaluator/
- http://eli.thegreenplace.net/2009/03/14/some-problems-of-recursive-descent-parsers/
- Top Down Operator Precendence:http://javascript.crockford.com/tdop/tdop.html
- Precendence Climbing Parsing:http://en.wikipedia.org/wiki/Operator-precedence_parser
-
本文向大家介绍Swift 编程语言入门教程,包括了Swift 编程语言入门教程的使用技巧和注意事项,需要的朋友参考一下 原文地址:http://gashero.iteye.com/blog/2075324 目录 1 简介 2 Swift入门 3 简单值 4 控制流 5 函数与闭包 6 对象与类 7 枚举与结构 1 简介 今天凌晨Apple刚刚发布了Swift编程语言
-
本文向大家介绍Nodejs极简入门教程(二):定时器,包括了Nodejs极简入门教程(二):定时器的使用技巧和注意事项,需要的朋友参考一下 setTimeout 和 clearTimeout setTimeout 用于设置一个回调函数 cb,其在最少 ms 毫秒后被执行(并非在 ms 毫秒后马上执行)。setTimeout 返回值可以作为 clearTimeout 的参数,clearTimeout
-
本文向大家介绍简述解释型和编译型编程语言相关面试题,主要包含被问及简述解释型和编译型编程语言时的应答技巧和注意事项,需要的朋友参考一下
-
本文向大家介绍JavaScript极简入门教程(一):基础篇,包括了JavaScript极简入门教程(一):基础篇的使用技巧和注意事项,需要的朋友参考一下 阅读本文需要有其他语言的编程经验。 开始学习之前 大多数的编程语言都存在好的部分和差的部分。本文只讲述 JavaScript 中好的部分,这是因为: 1.仅仅学习好的部分能够缩短学习时间 2.编写的代码更加健壮 3.编写的代码更加易读 4.编写
-
本文向大家介绍汇编语言入门教程阮一峰版,包括了汇编语言入门教程阮一峰版的使用技巧和注意事项,需要的朋友参考一下 汇编语言是一种最低级、最古老、不具有移植性的编程语言,它能够直接访问计算机硬件,所以执行效率极高,占用资源极少,一般用于嵌入式设备、驱动程序、实时应用、核心算法等。 汇编语言的缺点是开发周期特别长,实现一个简单的功能都非常麻烦,已经很少用来编写应用程序了。 学习编程其实就是学高级语言,即
-
本文向大家介绍Nodejs极简入门教程(一):模块机制,包括了Nodejs极简入门教程(一):模块机制的使用技巧和注意事项,需要的朋友参考一下 JavaScript 规范(ECMAScript)没有定义一套完善的能适用于大多数程序的标准库。CommonJS 提供了一套 JavaScript 标准库规范。Node 实现了 CommonJS 规范。 模块基础 在 Node 中,模块和文件是一一对应的。