
老生常谈JavaScript 正则表达式语法

JavaScript定义正则表达式有两种方法。
1.RegExp构造函数
var pattern = new RegExp("[bc]at","i");
它接收两个参数:一个是要匹配的字符串模式,另一个是可选的标志字符串。
2.字面量
var pattern = /[bc]at/i;
正则表达式的匹配模式支持三种标志字符串:
g:global,全局搜索模式,该模式将被应用于所有字符串,而并非搜索到第一个匹配项就停止搜索;
i:ingore case,忽略字母大小写,即在确定匹配项时忽略模式和字符串大小写;
m:multiple lines,多行模式,即在搜索到达一行文本末尾时会继续查找下一行是否有匹配项。
这两种创建正则表达式方法的不同之处在于,正则表达式字面量始终会共享同一个RegExp实例,而使用构造函数创建的每一个新RegExp实例都是新实例。
元字符
元字符是拥有特殊意义的字符,正则表达式的元字符主要有:
( [ { \ ^ $ | ) ? * + .
在不同的组合中元字符有其不同的意义。
预定义特殊字符

字符类 简单类
一般情况下正则表达式一个字符对应字符串一个字符,但我们可以使用[]来构建一个简单的类,来表示符合某一特征的一类字符。例如:
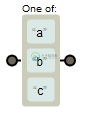
[abc]可以匹配方括号中的a、b、c或其任意组合的字符。
反向类
既然[]可以构建一个类,那么自然就会联想到与之对应的不包含括号中内容的类,这个类叫做反向类,例如[^abc]就可以匹配不是a或b或c的字符。
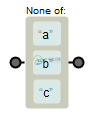
范围类
有时候一个一个字符匹配太麻烦而且匹配的类型也相同,此时我们可以使用"-"连接线来表示某个闭区间之间的内容,例如匹配所有小写字母可以使用[a-z],如下:

匹配所有的0到9简直的任意数字可以使用[0-9]表示:
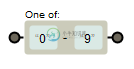
预定义类
对于如上我们创建的几个类,正则表达式为我们提供了几个常用的预定义类来匹配常见的字符,如下:
| 字符 | 等价类 | 含义 |
| . | [^\n\r] | 匹配除了回车符和换行符之外的所有字符 |
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \s | [\t\n\x0B\f\r] | 空白字符 |
| \S | [^\t\n\x0B\f\r] | 非空白字符 |
| \w | [a-zA-Z_0-9] | 单词字符(字母、数字和下划线) |
| \W | [^a-zA-Z_0-9] | 非单词字符 |
量词
上面的方法匹配字符都是一对一匹配的,如果某个字符连续出现多次按照上面的方法匹配会非常麻烦,因此我们想有没有其它方法可以直接匹配多次重复出现的字符。正则表达式为我们提供了一些量词,如下:
| 字符 | 含义 |
| ? | 出现零次或一次(最多一次) |
| + | 出现一次或多次(至少一次) |
| * | 出现零次或多次(任意次) |
| {n} | 出现n次 |
| {n,m} | 出现n到m次 |
| {n,} | 至少出现n次 |
贪婪模式与非贪婪模式
对于{n,m}这种匹配方式,到底是匹配n个还是匹配m个呢?这就涉及到匹配模式的问题。默认情况下,量词是尽可能多的匹配字符,也就是所谓的贪婪模式,例如:
var num = '123456789';
num.match(/\d{2,4}/g); //[1234]、[5678]、[9]
与贪婪模式对于的是非贪婪模式,只需要在量词之后加"?"即可,例如{n,m}?,就是按照最少的字符匹配,如下:
var num = '123456789';
num.match(/\d{2,4}?/g); //[12]、[34]、[56]、[78]、[9]
分组
量词只能是单个字符匹配多次,如果我们希望匹配某一组字符多次呢?正则表达式中小括号可以定义一个字符串整体为一个分组。
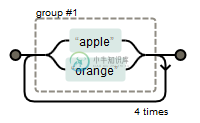
我们想要匹配apple这个单词出现4次可以这样匹配(apple){4},如下:
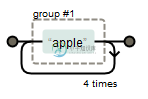
如果想要匹配apple或orange出现4次,可以插入管道符"|",例如:
(apple|orange){4}
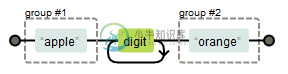
如果使用分组的正则表达式中出现多个小括号即多个分组,那么匹配结果就会把匹配项也分组并编号,例如:
(apple)\d+(orange)
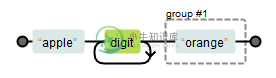
如果我们不希望捕获某些分组,只需要在分组的小括号前面紧跟一个问号和冒号即可,例如:
(?:apple)\d+(orange)
边界
正则表达式也为我们提供了几个常用的边界匹配字符,例如:
| 字符 | 含义 |
| ^ | 以xx开头 |
| $ | 以xx结尾 |
| \b | 单词边界,指[a-zA-Z_0-9]之外的字符 |
| \B | 非单词边界 |
其中单词边界匹配的是一个位置,这个位置的一侧是构成单词的字符,但另一侧为非单词字符、字符串的开始或结束位置。
前瞻
前瞻用来匹配接下来出现的是或不是某一个特定的字符集。
| 表达式 | 含义 |
| exp1(?=exp2) | 匹配后面是exp2的exp1 |
| exp1(?!exp2) | 匹配后面不是exp2的exp1 |
看一个例子:
apple(?=orange)
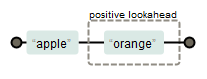
(/apple(?=orange)/).test('appleorange123'); //true
(/apple(?=orange)/).test('applepear345'); //false
再看另一个例子:
apple(?!orange)
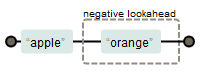
(/apple(?!orange)/).test('appleorange123'); //false
(/apple(?!orange)/).test('applepear345'); //true
以上这篇老生常谈JavaScript 正则表达式语法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍老生常谈JavaScript 函数表达式,包括了老生常谈JavaScript 函数表达式的使用技巧和注意事项,需要的朋友参考一下 JavaScript中创建函数主要有两种方法:函数声明和函数表达式。这两种方式都有不同的适用场景。这篇笔记主要关注的是函数表达式的几大特点以及它的使用场景,下面一一描述。 主要特点 •可选的函数名称 函数名称是函数声明的必需组成部分,这个函数名称相当于一个
-
主要内容:正则表达式元字符,贪婪模式非贪婪模式,正则表达式转义正则表达式(regular expression)是一种字符串匹配模式或者规则,它可以用来检索、替换那些符合特定规则的文本。正则表达式几乎适用于所有编程语言,无论是前端语言 JavaScript,还是诸如许多后端语言,比如 Python、Java、C# 等,这些语言都提供了相应的函数、模块来支持正则表达式,比如 Python 的 re 模块就提供了正则表达式的常用方法。 在使用 Python 编写
-
正则表达式是字符串处理的有力工具和技术,正则表达式使用预定义的特定模式去匹配一类具有共同特征的字符串,主要用于字符串处理,可以快速、准确地完成复杂的字符串查找、替换等处理要求。 常用的正则表达式元字符: 元字符|功能说明 :-:|- .|除换行符外的任意单个字符 *|0个或任意多个字符 +|1个或任意多个字符 -|用在 [ ] 中表示范围 ||两者中一个 ^|行首 $|行尾 ?|0个或1个字符 \
-
问题内容: 如何在JavaScript中使用支持Unicode的正则表达式? 例如,应该有类似的东西可以匹配Letters或Marks类别中的任何代码点(而不仅仅是ASCII的),并且希望具有这样的过滤器来标点,等等。 问题答案: ES 6的情况 即将发布的ECMAScript语言规范,版本6,包含可识别Unicode的正则表达式。必须使用u正则表达式上的修饰符启用支持。请参阅ES6中支持Unic
-
正则练习 1.生成一个正则表达式regexObj 描述字符串规则的表达式,两种方式 直接量: /pattren/attrs(/规则/属性) 对象构造方式:new RegExp(pattern,arrtes) (/规则/属性) 2.regexObj.test(str) 测试正则表达式regexObj与指定字符串是否匹配 /10086/.test('10086') //true /10086/.tes
-
本文向大家介绍javascript正则表达式定义(语法)总结,包括了javascript正则表达式定义(语法)总结的使用技巧和注意事项,需要的朋友参考一下 本文讲述了javascript正则表达式定义(语法)。分享给大家供大家参考,具体如下: 正则表达式的2种定义方法:一种是直接调用RegExp(),第二种是直接用字面量来定义,即var re = /正则规则/; 2种定义方法本质都是调用RegEx