
说说node中的可读流和可写流的区别

前言
nodejs中大量的api与流有关,曾经看到公司的一些大神的node代码,实现一个接口只需要pipe一下另一个java接口就可以了。简单的一行代码实在让人困惑。作为小白的自己一脸懵逼却又不敢问,因为根本不知道从何问起。现在终于通过学习,也能对流说出个123,希望和大家共同交流。
流简介
流分为缓冲模式和对象模式,缓冲模式只能处理buffer或字符串,对象模式可以处理js对象。流又分为四种类型:可读流、可写流、双工流和转换流。后两种其实是对可读和可写流的应用。所以我想先聊聊可读流和可写流。
可读流
可读流有两种模式,并随时可以转换,我们可以通过监听可读流的事件来操作它。
两种模式(引用自node中文网的描述):
1、流动模式:可读流自动读取数据,通过EventEmitter接口的事件尽快将数据提供给应用。
2、暂停模式:必须显式调用stream.read()方法来从流中读取数据片段。
暂停模式切换到流动模式的api有:
1、监听“data”事件
2、调用 stream.resume()方法
3、调用 stream.pipe()方法将数据发送到可写流
流动模式切换到暂停模式的api有:
1、如果不存在管道目标,调用stream.pause()方法
2、如果存在管道目标,调用 stream.unpipe()并取消'data'事件监听
可读流事件:'data','readable','error','close','end'
可写流
可写流相对较为简单,我们也可以通过监听它的事件来操作它。
可写流事件: 'close','drain','error','finish','pipe','unpipe'
举个栗子
我以一个简单的例子描述一个流最常见的场景,谈谈对这个过程的理解。例子就是:我要读取一个文件,然后把它的内容写到另一个文件(当然是用“流”的api,而不是用‘fs'模块的api)。
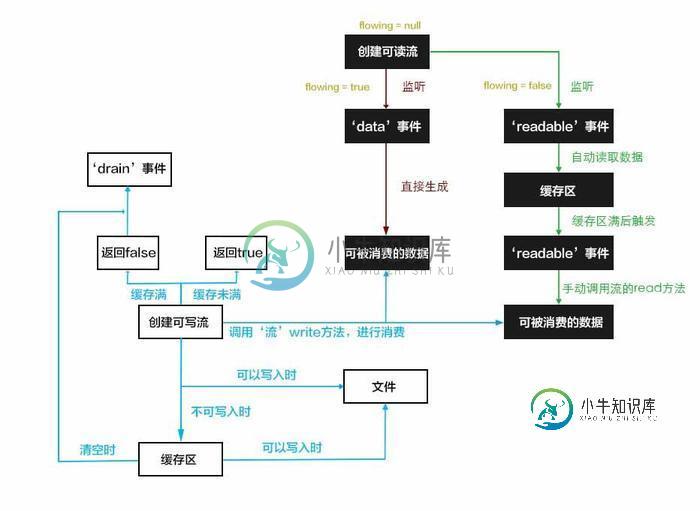
接下来我解释一下这张图:
如上图,当我们创建了一个可读流的时候,readable._readableState.flowing属性默认为null,这时我们有两种选择:
1、监听‘readable'事件,这时可读流会读取64k(可以在创建可读流时,通过option参数中的highWaterMark更改)数据到流的缓存区中,等待你用read方法去读取并消费数据,当你用read方法读了64k数据之后,会再次触发readable事件,直到你读完了源文件的所有数据。记住,之所以叫暂停模式是因为如果你不调用read方法,代码永远会停在这里,什么事情也不会发生了。
2、如果你选择监听‘data'事件,可读流会直接读取64k数据并通过‘data'事件的回掉函数提供给你消费,并且这个过程不会停止,如果源文件中有很多数据,会不停的触发‘data'事件,直到全部读取完成。当然,在这个过程中你随时可以通过stream.pause()方法暂停它。
那么,这两种模式有什么区别呢?在我理解,如果你不需要对数据进行精确控制,首先选择流动模式,因为它的效率更高。如果需要对流的过程进行精确控制则可以选择暂停模式。也就是说暂停模式是流更高级一些的用法。其实官方建议我们尽量不要手动去操作流,如果可以,尽量使用pipe方法。
接下来,不论我们以哪种方式读到了文件中的数据,这时我们都可以创建一个可写流并调用可写流的write方法来消费读到的数据。调用write方法会向文件中写入数据,但是因为写入的速度较慢,如果当前写入还在进行,而你又调用了write方法,node会将你要写入的数据缓存在一个缓存区中,等到文件写入完毕会从缓存区中取出数据,继续写入。
write方法拥有一个布尔类型的返回值,用来表示目前是否还可以继续调用write方法写入内容。如果返回false,我们应当停止读取数据以避免消耗过多内存。那么什么时候会返false呢?就是当缓存区的大小大于16k(可以在创建可读流时,通过option参数中的highWaterMark更改)时。
缓存区满后,文件写入一直在进行,不一会儿会把缓存区的内容全部写入,缓存区处于清空状态,这时会触发可写流的‘drain'事件,这时我们可以继续向文件写入数据了。注意:如果缓存区从未满过,‘drain'事件永远也不会触发。
那么这张图对应到代码是什么样的呢:
let fs = require('fs');
//创建可读可写流
let rs = fs.createReadStream('./1.txt');
let ws = fs.createWriteStream('./2.txt');
//监听‘data'事件,开启流动模式
rs.on('data',function (data) {
//对应图中的可写流true和false
let flag = ws.write(data);
if(!flag){
//如果可写流返回false,我们应当停止读取,以避免消耗过多内存
rs.pause();
}
});
//对应图中的drain事件
ws.on('drain',function () {
//重新开启流动模式
rs.resume();
});
//使用可读流的暂停模式
function read() {
let data = rs.read()
let flag = ws.write(data);
if(flag){
read()
}
}
rs.on('readable',function(){
read()
})
ws.on('drain',function () {
read()
});
结尾
可读和可写流的用法和api还有很多,这里只是简单的梳理了一下基本过程,如果有描述不准确的地方还请大家在评论区多指正。
参考资料
- https://nodejs.org/dist/latest-v8.x/docs/api/stream.html
- http://nodejs.cn/api/
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍浅谈手写node可读流之流动模式,包括了浅谈手写node可读流之流动模式的使用技巧和注意事项,需要的朋友参考一下 node的可读流基于事件 可读流之流动模式,这种流动模式会有一个"开关",每次当"开关"开启的时候,流动模式起作用,如果将这个"开关"设置成暂停的话,那么,这个可读流将不会去读取文件,直到将这个"开关"重新置为流动。 读取文件流程 读取文件内容的流程,主要为: 打开文件,
-
本文向大家介绍说说前端中的事件流?相关面试题,主要包含被问及说说前端中的事件流?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: HTML中与javascript交互是通过事件驱动来实现的,例如鼠标点击事件onclick、页面的滚动事件onscroll等等,可以向文档或者文档中的元素添加事件侦听器来预订事件。想要知道这些事件是在什么时候进行调用的,就需要了解一下“事件流”的概念。 什么是事件
-
本文向大家介绍说说Redux的实现流程相关面试题,主要包含被问及说说Redux的实现流程时的应答技巧和注意事项,需要的朋友参考一下 组件视图 通过 事件 发送 dispatch action store 接收到 action , 把action和 oldState 当做参数发送给 reducers reducers 接收 action和 oldState 通过计算返回新的 newState 给 s
-
本文向大家介绍请说说koa的app.use()执行流程相关面试题,主要包含被问及请说说koa的app.use()执行流程时的应答技巧和注意事项,需要的朋友参考一下 ,简单说其实就是把函数存放到数组里,然后返回实例对象。 中详细点,则是判断是generator函数,用(其实用的是)转换一次,再存放到数组里。 真正执行是。 具体源码可以看我这篇文章。 若川:学习 koa 源码的整体架构,浅析koa洋葱
-
本文向大家介绍说说你对单向数据流和双向数据流的理解相关面试题,主要包含被问及说说你对单向数据流和双向数据流的理解时的应答技巧和注意事项,需要的朋友参考一下 单向数据流:所有状态的改变可记录、可跟踪,源头易追溯;所有数据只有一份,组件数据只有唯一的入口和出口,使得程序更直观更容易理解,有利于应用的可维护性;一旦数据变化,就去更新页面(data-页面),但是没有(页面-data);如果用户在页面上做了
-
本文向大家介绍请说说json和jsonp的区别?相关面试题,主要包含被问及请说说json和jsonp的区别?时的应答技巧和注意事项,需要的朋友参考一下 json是一种数据结构 jsonp是一种跨域技术: 跨域是后端收到了请求并处理返回给前端,但浏览器发现跨域了抛出错误中止了请求, 因为script标签支持跨域运行, 后端根据前端请求动态生成*.js文件,前端构造script标签加载js文件,Js文