
基于Python中random.sample()的替代方案

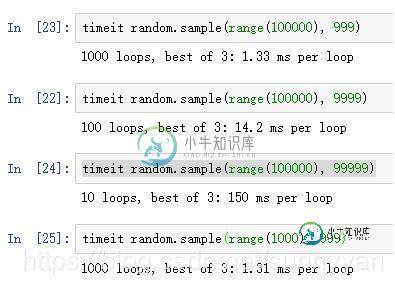
python中random.sample()方法可以随机地从指定列表中提取出N个不同的元素,但在实践中发现,当N的值比较大的时候,该方法执行速度很慢,如:
numpy random模块中的choice方法可以有效提升随机提取的效率:
需要注意的是,需要置replace为False,即抽取的元素不能重复,默认为True。

补充知识:Python: random模块的随即取样函数:choice(),choices(),sample()
choice(seq): 从seq序列中(可以是列表,元组,字符串)随机取一个元素返回
choices(population, weights=None, *, cum_weights=None, k=1):
从population中进行K次随机选取,每次选取一个元素(注意会出现同一个元素多次被选中的情况),weights是相对权重值,population中有几个元素就要有相对应的weights值,cum_weights是累加权重值,例如,相对权重〔10, 5, 30,5〕相当于累积权重〔10, 15, 45,50〕。
在内部,在进行选择之前,相对权重被转换为累积权重,因此提供累积权重节省了工作。返回一个列表。
sample(population, k)从population中取样,一次取k个,返回一个k长的列表。
可以像这样使用sample(range(10000000), k=60)
以上这篇基于Python中random.sample()的替代方案就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 我用Google搜索了很多,但是找不到。我想知道方法的用途,它有什么作用?什么时候应该使用它以及一些示例用法。 问题答案: 根据文件: random.sample(人口,k) 返回从填充序列中选择的唯一元素的ak长度列表。用于随机抽样而无需更换。 基本上,它从序列中选择k个唯一的随机元素(样本): 也可以直接从以下范围工作: 除了序列,还可以使用集合: 但是,不适用于任意迭代器:
-
在为另一种语言构建解释器时,通常建议创建一个基于堆栈的虚拟机,该虚拟机可以解释实际解释器生成的字节码。然后,解释器将由两部分组成:翻译器,它将高级语言的指令转换为虚拟机的字节码,以及虚拟机本身。 我的问题是:口译语言有哪些替代方案?例如,跳过虚拟机并使用C中的函数实现所有指令是否可能(而且切实可行)?在某种程度上,在我看来这应该是可能的,但也许您最终会实现某种类型的最小VM,以实现更复杂的功能。还
-
当我使用@PostConstruct或InitializingBean.AfterPropertiesSet时,initMethodName为空。因此,这些都不是XML配置(init-method=“some”)的确切替代方案。 我想知道这种微小的不一致背后的原因。以及在Java中设置init-method的方法。
-
问题内容: 我目前有这样的代码: 但是,这可能会在将来导致难以发现的错误,因为读者可能不会注意到上面出现的错误。或者,贡献者可能会错误地添加,而忘记添加。 我如何避免这种陷阱? 问题答案: 这样,实际上是一个“全局”。可以从任何地方对其进行读写。 与字典的替代方法相比,我更喜欢这种方法,因为它可以自动完成变量名。
-
这是python中的合并排序逻辑:(这是第一部分,忽略函数merge())问题的关键是将递归逻辑转换为while循环。代码礼貌:Rosettacode合并排序 是否有可能使其成为一种动态的在同时循环,而每个左和右数组分成两个,一种指针根据左和右数组的数量不断增加并打破它们,直到只剩下单个长度大小的列表?因为每次在左和右侧进行下一次拆分时,数组都会不断分解,直到只剩下单个长度列表,因此左侧(左-左,
-
我在写一个背包问题的代码。有一个有重量容量的背包,你选择一个特定的项目组合,以找到最好的解决方案。然而,我试图随机生成可能的解决方案。因此,我的代码将选择随机数量的随机项(生成一个随机大小的列表),并测试解决方案是否可行(小于容量)或不可行(大于容量)。但是我对random.sample()有问题。为了得到一个随机大小的列表,我将k设置为leng(一个随机整数),总体是从给定的项目范围中挑选的项目