
SQLServer地址搜索性能优化

这是一个很久以前的例子,现在在整理资料时无意发现,就拿出来再改写分享。
1.需求
1.1 基本需求: 根据输入的地址关键字,搜索出完整的地址路径,耗时要控制在几十毫秒内。
1.2 数据库地址表结构和数据:
表TBAddress
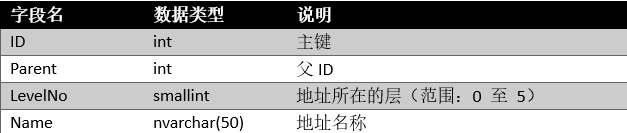
表数据
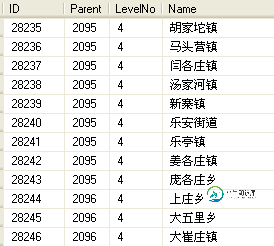
1.3 例子:
e.g. 给出一个字符串如“广 大”,找出地址全路径中包含有“广” 和“大”的所有地址,結果如下:

下面将通过4个方法来实现,再分析其中的性能优劣,然后选择一个比较优的方法。
2.创建表和插入数据
2.1 创建数据表TBAddress
use test;
go
/* create table */
if object_id('TBAddress') is not null
drop table TBAddress;
go
create table TBAddress
(
ID int ,
Parent int not null ,
LevelNo smallint not null ,
Name nvarchar(50) not null ,
constraint PK_TBAddress primary key ( ID )
);
go
create nonclustered index ix_TBAddress_Parent on TBAddress(Parent,LevelNo) include(Name) with(fillfactor=80,pad_index=on);
create nonclustered index ix_TBAddress_Name on TBAddress(Name)include(LevelNo)with(fillfactor=80,pad_index=on);
go
create table
2.2 插入数据
use test
go
/*insert data*/
set nocount on
Begin Try
Begin Tran
Insert Into TBAddress ([ID],[Parent],[LevelNo],[Name])
Select 1,0,0,N'中国' Union All
Select 2,1,1,N'直辖市' Union All
Select 3,1,1,N'辽宁省' Union All
Select 4,1,1,N'广东省' Union All
... ...
Select 44740,930,4,N'奥依塔克镇' Union All
Select 44741,932,4,N'巴音库鲁提乡' Union All
Select 44742,932,4,N'吉根乡' Union All
Select 44743,932,4,N'托云乡'
Commit Tran
End Try
Begin Catch
throw 50001,N'插入數據過程中發生錯誤.' ,1
Rollback Tran
End Catch
go
附件: insert Data
Note: 数据有44700条,insert代码比较长,所以采用附件形式。
3.测试,方法1
3.1 分析:
a. 先搜索出包字段Name中含有“广”、“大”的所有地址记录存入临时表#tmp。
b. 再找出#tmp中各个地址到Level 1的全路径。
c. 根据步骤2所得的结果,筛选出包含有“广”和“大”的地址路径。
d. 根据步骤3筛选的结果,查询所有到Level n(n为没有子地址的层编号)的地址全路径。
3.2 存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV0]') is not null
Drop Procedure [up_SearchAddressByNameV0]
Go
create proc up_SearchAddressByNameV0
(
@Name nvarchar(200)
)
As
set nocount on
declare @sql nvarchar(max)
declare @tmp Table (Name nvarchar(50))
set @Name=@Name+' '
while patindex('% %',@Name)>0
begin
set @Name=replace(@Name,' ',' ')
end
set @sql ='select ''' +replace(@Name,' ',''' union all select ''')+''''
insert into @tmp(Name) exec(@sql)
if object_id('tempdb..#tmp') is not null drop table #tmp
if object_id('tempdb..#') is not null drop table #
create table #tmp(ID int )
while @Name>''
begin
insert into #tmp(ID)
select a.ID from TBAddress a where a.Name like '%'+substring(@Name,1,patindex('% %',@Name)-1)+'%'
set @Name=Stuff(@Name,1,patindex('% %',@Name),'')
end
;with cte_SearchParent as
(
select a.ID,a.Parent,a.LevelNo,convert(nvarchar(500),a.Name) as AddressPath from TBAddress a where exists(select 1 from #tmp x where a.ID=x.ID)
union all
select a.ID,b.Parent,b.LevelNo,convert(nvarchar(500),b.Name+'/'+a.AddressPath) as AddressPath
from cte_SearchParent a
inner join TBAddress b on b.ID=a.Parent
--and b.LevelNo=a.LevelNo -1
and b.LevelNo>=1
)
select a.ID,a.AddressPath
into #
from cte_SearchParent a
where a.LevelNo=1 and exists(select 1 from @tmp x where a.AddressPath like '%'+x.Name+'%' having count(1)=(select count(1) from @tmp))
;with cte_result as
(
select a.ID,a.LevelNo,b.AddressPath
from TBAddress a
inner join # b on b.ID=a.ID
union all
select b.ID,b.LevelNo,convert(nvarchar(500),a.AddressPath+'/'+b.Name) As AddressPath
from cte_result a
inner join TBAddress b on b.Parent=a.ID
--and b.LevelNo=a.LevelNo+1
)
select distinct a.ID,a.AddressPath
from cte_result a
where not exists(select 1 from TBAddress x where x.Parent=a.ID)
order by a.AddressPath
Go
procedure:up_SearchAddressByNameV0
3.3 执行查询:
exec up_SearchAddressByNameV0 '广 大'

共返回195行记录。
3.4 客户端统计信息:
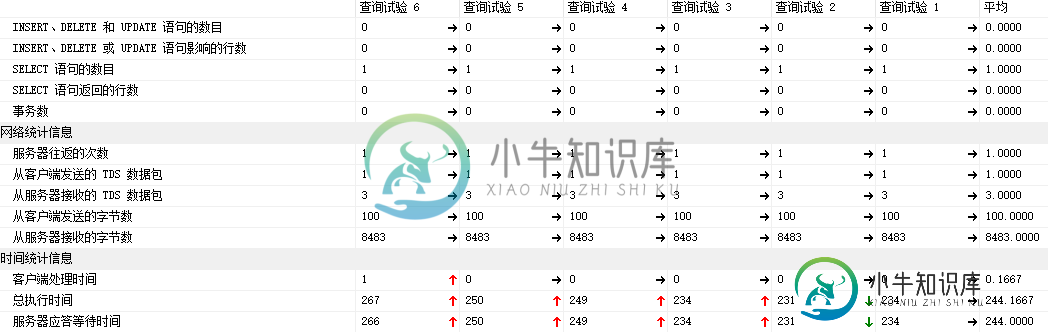
平均的执行耗时: 244毫秒
4.测试,方法2
方法2是参照方法1,并借助全文索引来优化方法1中的步骤1。也就是在name列上建立全文索引,在步骤1中,通过全文索引搜索出包字段Name中含有“广”、“大”的所有地址记录存入临时表#tmp,其他步骤保持不变。
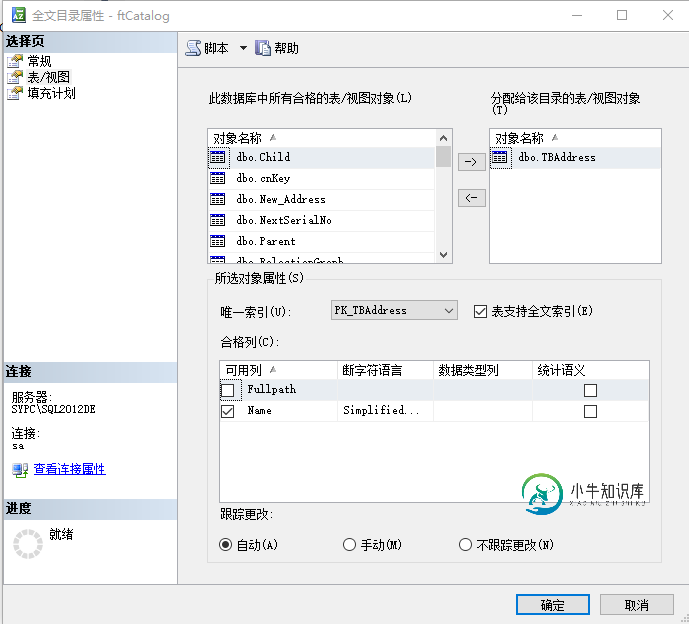
4.1 创建全文索引
use test go /*create fulltext index*/ if not exists(select 1 from sys.fulltext_catalogs a where a.name='ftCatalog') begin create fulltext catalog ftCatalog As default; end go --select * From sys.fulltext_languages create fulltext index on TBAddress(Name language 2052 ) key index PK_TBAddress go alter fulltext index on dbo.TBAddress add(Fullpath language 2052) go
Note: 在Name列上创建全文索引使用的语言是简体中文(Simplified Chinese)
4.2 存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV1]') is not null
Drop Procedure [up_SearchAddressByNameV1]
Go
create proc up_SearchAddressByNameV1
(
@Name nvarchar(200)
)
As
set nocount on
declare @sql nvarchar(max),@contains nvarchar(500)
declare @tmp Table (Name nvarchar(50))
while patindex('% %',@Name)>0
begin
set @Name=replace(@Name,' ',' ')
end
set @sql ='select ''' +replace(@Name,' ',''' union all select ''')+''''
set @contains='"'+replace(@Name,' ','*" Or "')+'*"'
insert into @tmp(Name) exec(@sql)
if object_id('tempdb..#') is not null drop table #
;with cte_SearchParent as
(
select a.ID,a.Parent,a.LevelNo,convert(nvarchar(2000),a.Name) as AddressPath from TBAddress a where exists(select 1 from TBAddress x where contains(x.Name,@contains) And x.ID=a.ID)
union all
select a.ID,b.Parent,b.LevelNo,convert(nvarchar(2000),b.Name+'/'+a.AddressPath) as AddressPath
from cte_SearchParent a
inner join TBAddress b on b.ID=a.Parent
--and b.LevelNo=a.LevelNo -1
and b.LevelNo>=1
)
select a.ID,a.AddressPath
into #
from cte_SearchParent a
where a.LevelNo=1 and exists(select 1 from @tmp x where a.AddressPath like '%'+x.Name+'%' having count(1)=(select count(1) from @tmp))
;with cte_result as
(
select a.ID,a.LevelNo,b.AddressPath
from TBAddress a
inner join # b on b.ID=a.ID
union all
select b.ID,b.LevelNo,convert(nvarchar(2000),a.AddressPath+'/'+b.Name) As AddressPath
from cte_result a
inner join TBAddress b on b.Parent=a.ID
--and b.LevelNo=a.LevelNo+1
)
select distinct a.ID,a.AddressPath
from cte_result a
where not exists(select 1 from TBAddress x where x.Parent=a.ID)
order by a.AddressPath
Go
procedure:up_SearchAddressByNameV1
4.3测试存储过程:
exec up_SearchAddressByNameV1 '广 大'

共返回195行记录。
4.4 客户端统计信息:
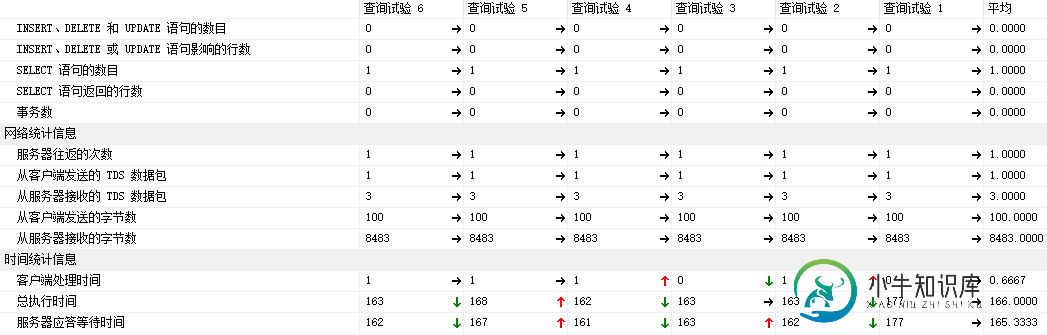
平均的执行耗时: 166毫秒
5.测试,方法3
在方法2中,我们在Name列上创建全文索引提高了查询性能,但我们不仅仅局限于一两个方法,下面我们介绍第3个方法。
第3个方法,通过修改表的结构和创建全文索引。在表TBAddress增加多一个字段FullPath存储各个地址到Level 1的全路径,再在FullPath列上创建全文索引,然后直接通过全文索引来搜索FullPath列中包含“广”和“大”的记录。
5.1 新增加字段FullPath,并更新列FullPath数据:
use test;
go
/*alter table */
if not exists ( select 1
from sys.columns a
where a.object_id = object_id('TBAddress')
and a.name = 'Fullpath' )
begin
alter table TBAddress add Fullpath nvarchar(200);
end;
go
create nonclustered index IX_TBAddress_FullPath on dbo.TBAddress(Fullpath) with(fillfactor=80,pad_index=on);
go
/*update TBAddress */
with cte_fullPath
as ( select ID, Parent, LevelNo, convert(nvarchar(500), isnull(Name, '')) as FPath, Fullpath
from dbo.TBAddress
where LevelNo = 1
union all
select A.ID, A.Parent, A.LevelNo, convert(nvarchar(500), B.FPath + '/' + isnull(A.Name, '')) as FPath, A.Fullpath
from TBAddress as A
inner join cte_fullPath as B on A.Parent = B.ID
)
update a
set a.Fullpath = isnull(b.FPath, a.Name)
from dbo.TBAddress a
left join cte_fullPath b on b.ID = a.ID;
go
5.2 在列FullPath添加全文索引:
alter fulltext index on dbo.TBAddress add(Fullpath language 2052)
5.3 存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV2]') is not null
Drop Procedure [up_SearchAddressByNameV2]
Go
create proc up_SearchAddressByNameV2
(
@name nvarchar(200)
)
As
declare @contains nvarchar(500)
set nocount on
set @contains='"'+replace(@Name,' ','*" And "')+'*"'
select id,FullPath As AddressPath from TBAddress a where contains(a.FullPath,@contains) and not exists(select 1 from TBAddress x where x.Parent=a.ID) order by AddressPath
Go
procedure:up_SearchAddressByNameV2
5.4 测试存储过程:
exec up_SearchAddressByNameV2 '广 大'

共返回195行记录。
5.5 客户端统计信息:
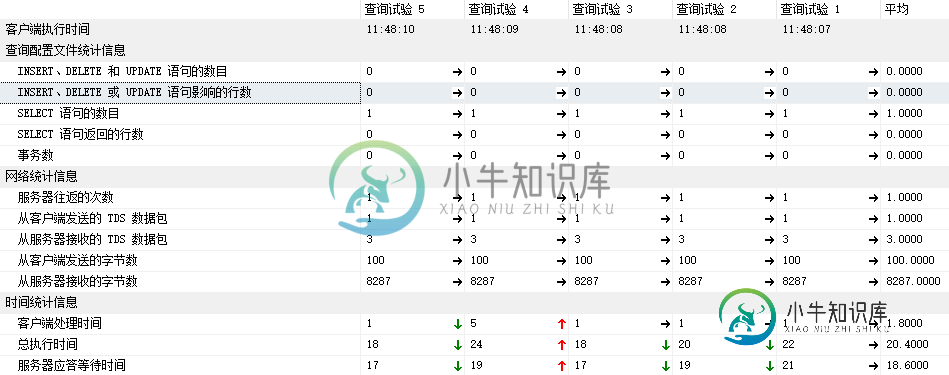
平均的执行耗时: 20.4毫秒
6.测试,方法4
直接使用Like对列FullPath进行查询。
6.1存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV3]') is not null
Drop Procedure [up_SearchAddressByNameV3]
Go
create proc up_SearchAddressByNameV3
(
@name nvarchar(200)
)
As
set nocount on
declare @sql nvarchar(max)
declare @tmp Table (Name nvarchar(50))
set @Name=rtrim(rtrim(@Name))
while patindex('% %',@Name)>0
begin
set @Name=replace(@Name,' ',' ')
end
set @sql='select id,FullPath As AddressPath
from TBAddress a where not exists(select 1 from TBAddress x where x.Parent=a.ID)
'
set @sql +='And a.FullPath like ''%' +replace(@Name,' ','%'' And a.FullPath Like ''%')+'%'''
exec (@sql)
Go
procedure:up_SearchAddressByNameV3
6.2 测试存储过程:
exec up_SearchAddressByNameV3 '广 大'

共返回195行记录。
6.3 客户端统计信息
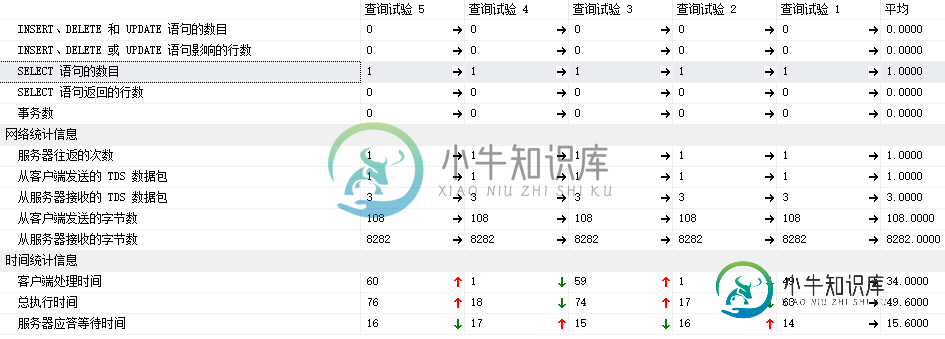
平均的执行耗时: 34毫秒
7.小结
这里通过一个简单的表格,对方法1至方法4作比较。

从平均耗时方面分析,一眼就知道方法3比较符合开始的需求(耗时要控制在几十毫秒内)。
当然还有其他的方法,如通过程序实现,把数据一次性加载至内存中,再通过程序写的算法进行搜索,或通过其他工具如Lucene来实现。不管哪一种方法,我们都是选择最优的方法。实际的工作经验告诉我们,在实际应用中,多选择和测试不同的方法来,选择其中一个满足我们环境的,而且是最优的方法。
-
我对DS和算法相当陌生,最近在一次工作面试中,我被问到一个关于性能调优和代码的问题。我们有一个包含数十亿个条目的数据结构,我们需要在该数据结构中搜索特定的单词。那么,我们可以使用哪种Java特性/库在尽可能快的时间内进行搜索呢? 当时我想不出确切的答案,所以我写道: 我们可以将值存储在地图中,并在地图中搜索单词(但在如何确定地图中的键值对方面遇到了困难) 我如何才能理解这个问题的确切答案,以及什么
-
问题内容: 我们有两个节点的集群(私有云中的VM,64GB的RAM,每个节点8个核心CPU,CentOS),几个小索引(约100万个文档)和一个大索引,约有2.2亿个文档(2个分片,170GB)的空间)。每个盒上分配了24GB的内存用于elasticsearch。 文件结构: 运行以下查询大约需要1-2秒: 我们是在此时达到硬件极限,还是有办法优化查询或数据结构以提高性能? 提前致谢! 问题答案:
-
本文转载自 developers.google.com 作者:Eiji Kitamura 原文链接:搜索优化 网站的访问者不只有人类,还有搜索引擎网络抓取工具。了解如何改善您的网站的搜索精度和排名。 确定网页的网址结构。 自适应设计是最受推崇的设计方法。 为独立的桌面版本/移动版本网站使用 rel='canonical' + rel='alternate'。 为动态提供独立桌面版本/移动版本 HT
-
假设我有三个指数:城市、博物馆和景点。 现在我正在查询一个术语的所有索引(),例如“维也纳” 作为结果,我得到: 维也纳:维也纳艺术博物馆 有没有办法优先考虑指数,这样我就可以得到第一个城市,而不是景点,最后是博物馆,就像这样: 维也纳 维也纳的Riesenrad 维也纳:维也纳艺术博物馆 维也纳:维也纳历史博物馆
-
本文向大家介绍mysql性能优化之索引优化,包括了mysql性能优化之索引优化的使用技巧和注意事项,需要的朋友参考一下 作为免费又高效的数据库,mysql基本是首选。良好的安全连接,自带查询解析、sql语句优化,使用读写锁(细化到行)、事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表记录可达百万级),如果是InnoDB,还可在崩溃后进行完整的恢复,优点非常多
-
Spark 是一个并行数据处理框架,这意味着任务应该在离数据尽可能近的地方执行(既 最少的数据传输)。 检查本地性 检查任务是否在本地运行的最好方式是在 Spark UI 上查看 stage 信息,注意下面截图中的 "Locality Level" 列显示任务运行在哪个地方。 调整本地性配置 你可以调整 Spark 在每个数据本地性阶段(data local --> process local -