
jupyter notebook参数化运行python方式

Updates
(2019.8.14 19:53)吃饭前用这个方法实战了一下,吃完回来一看好像不太行:跑完一组参数之后,到跑下一组参数时好像没有释放之占用的 GPU,于是 notebook 上的结果,后面好几条都报错说 cuda out of memory。
现在改成:将 notebook 中的代码写在一个 python 文件中,然后用命令行运行这个文件,比如:
# autorun.py import os # print(os.getcwd()) over = [ # 之前手工改参数跑完的参数组合 [0, 1, 1], [0, 1, 2], [0, 1, 3], [0, 2, 1], [1, 0, 1], [1, 2, 1] ] for alpha in range(1, 4, 1): for beta in range(3): for gamma in range(3): if [alpha, beta, gamma] in over: continue os.system(f'python main.py --alpha {alpha} --beta {beta} --gamma {gamma}')
这里的 main.py 是训练用的主文件。改在 py 里用 os.system 跑,希望跑一组参数之后完会自动释放资源再跑下一组(?)
Notes
有多组参数组合需要尝试,不想每组参数都人工修改 python 代码,再在 notebook 中 %run 它。
python 参数通过的 argparse 接收,在 notebook 中写个多重循环遍历参数组合传给 python 程序自动运行。
记录一个简例。
Codes
test_dir
|- test.py
|- test.ipynb
in py file
# test.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--number', type=int, default=0, help='number')
parser.add_argument('--string', type=str, default='abc', help='string')
args = parser.parse_args()
print('number:', args.number, type(args.number))
print('string:', args.string, type(args.string))
in notebook
注意传参数时 $ 的使用
# test.ipynb
for i in range(3):
for s in ('a', 'b', 'c'):
%run test.py --number $i --string $s
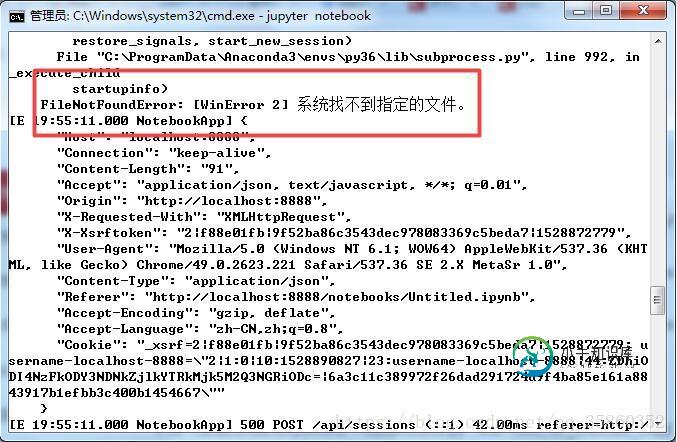
补充知识:Jupyter Notebook出现kernel error FileNotFoundError: [WinError 2] 系统找不到指定的文件
Jupyter Notebook出现kernel error
conda create -n py36 --clone root
当时用Anaconda克隆本地的环境root到自己创建的py36环境,由于克隆完成后我又更改了虚拟环境名称,所以导致启动
jupyter notebook 进入文件是不能找到连接文件。
File”//anaconda/lib/python2.7/site-packages/jupyter_client/manager.py”, line 190, in _launch_kernel
return launch_kernel(kernel_cmd, **kw)
File “//anaconda/lib/python2.7/site-packages/jupyter_client/launcher.py”, line 123, in launch_kernel
proc = Popen(cmd, **kwargs)
File “//anaconda/lib/python2.7/subprocess.py”, line 710, in init
errread, errwrite)
File “//anaconda/lib/python2.7/subprocess.py”, line 1335, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or director
解决办法
首先在cmd 使用jupyter kernelspec list查看安装的内核和位置
进入安装内核目录打开kernel.jason文件,查看Python编译器的路径是否正确
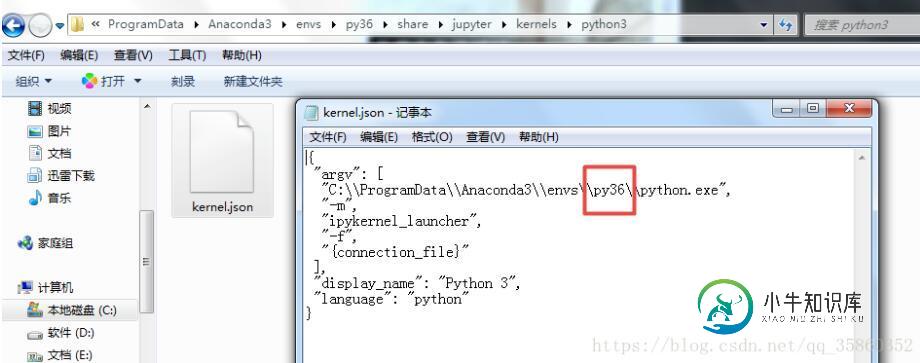
如果不正确python -m ipykernel install --user重新安装内核,如果有多个内核,如果你使用conda create -n python2 python=2,为Python2.7设置conda变量,那么在anacoda下使用activate pyhton2切换python环境,重新使用python -m ipykernel install --user安装内核.(通用情况)
或者直接进入kernel.json里更改py36(这是属于我的情况)
重启jupyter notebook即可。
以上这篇jupyter notebook参数化运行python方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 标准接口只有非参数化方法。也有接口与泛型类型的方法返回结果。我需要传递通用参数,如下所示: 是否有用于此目的的标准接口,或者我必须自己声明该基本接口? 问题答案: 通常,您将实现或作为支持通用输入参数的类;例如
-
问题内容: 我想从C调用Python脚本,并传递脚本中所需的一些参数。 我要使用的脚本是mrsync或多播远程同步。我通过调用以下命令从命令行进行了工作: -m是包含目标ip地址的列表。-s是包含要同步的文件的目录。-t是目标计算机上将放置文件的目录。 到目前为止,通过使用以下C程序,我设法运行了没有参数的Python脚本: 这很好。但是,我找不到如何将这些参数传递给方法的方法。 问题答案: 似乎
-
运行参数 如果 qemu 使用的是默认 /usr/local/bin 安装路径,则在命令行中可以直接使用 qemu 命令运行程序。qemu 运行可以有多参数,格式如: qemu [options] [disk_image] 其中 disk_image 即硬盘镜像文件。 部分参数说明: `-hda file' `-hdb file' `-hdc file' `-hdd file'
-
我正在尝试为Google Cloud Dataflow创建自己的模板,这样作业就可以从GUI执行,让其他人更容易执行。我遵循了教程,创建了自己的PipelineOptions类,并用parser.add_value_provider_argument()方法填充了它。然后,当我尝试使用my_options.argname.get()将这些参数传递到管道中时,我会得到一个错误,告诉我该项不是从运行时
-
大家好,堆栈溢出。今天,我想问一些非常不同的问题。 我目前是一名数据科学家,我在JupyterLab/笔记本上做了很多工作。我的几个同事用笔记本电脑代替了JupyterLab。看起来这两者之间并没有太大区别(我真的很喜欢JupyterLab以不同的颜色呈现代码的方式)。我在网上搜索过,上面写着 "JupyterLab是下一代的Jupyter笔记本" 然而,一些特写,如情节人物,在JupyterLa
-
问题内容: 由于重复的注释,以下代码无效: 但是,如何结合使用这两个注释? 问题答案: 至少有两个选项可以做到这一点: 以下http://www.blog.project13.pl/index.php/coding/1077/runwith-junit4-with-both-springjunit4classrunner-and-parameterized/ 您的测试需要看起来像这样: 有一个gi