
Transactional replication(事务复制)详解之如何跳过一个事务

在transactional replication, 经常会遇到数据同步延迟的情况。有时候这些延迟是由于在publication中执行了一个更新,例如update ta set col=? Where ?,这个更新包含巨大的数据量。在subscription端,这个更新会分解成多条命令(默认情况下每个数据行一个命令),应用到subscription上。 不得已的情况下,我们需要跳过这个大的事务,让replication继续运行下去。
现在介绍一下transactional replication的一些原理和具体的方法
当publication database的article发生更新时, 会产生相应的日志,Log reader会读取这些日志信息,将他们写入到Distribution 数据库的msrepl_transactions和msrepl_commands中。
Msrepl_transactions中的每一条记录都有一个唯一标识xact_seqno,xact_seqno对应日志中的LSN。 所以可以通过xact_seqno推断出他们在publication database中的生成顺序,编号大的生成时间就晚,编号小的生成时间就早。
Distributionagent包含两个子进程,reader和writer。 Reader负责从Distribution 数据库中读取数据,Writer负责将reader读取的数据写入到订阅数据库.
reader是通过sp_MSget_repl_commands来读取Distribution数据库中(读取Msrepl_transactions表和Msrepl_Commands表)的数据
下面是sp_MSget_repl_commands的参数定义
CREATE PROCEDURE sys.sp_MSget_repl_commands ( @agent_id int, @last_xact_seqno varbinary(16), @get_count tinyint = 0, -- 0 = no count, 1 = cmd and tran (legacy), 2 = cmd only @compatibility_level int = 7000000, @subdb_version int = 0, @read_query_size int = -1 )
这个存储过程有6个参数,在Transactional replication 中,只会使用前4个(并且第三个参数和第四个参数的值是固定不变的.分别为0和10000000)。下面是一个例子:
execsp_MSget_repl_commands 46,0x0010630F000002A900EA00000000,0,10000000
@agent_id表示Distributionagentid,每个订阅都会有一个单独的Distributionagent来处理数据。 带入@agent_id后,就可以找到订阅对应的publication 和所有的article。
@last_xact_seqno 表示上一次传递到订阅的LSN。
大致逻辑是:Reader读取subscription database的MSreplication_subscriptions表的transaction_timestamp列,获得更新的上一次LSN编号,然后读取分发数据库中LSN大于这个编号的数据。 Writer将读取到的数据写入订阅,并更新MSreplication_subscriptions表的transaction_timestamp列。然后Reader会继续用新的LSN来读取后续的数据,再传递给Writer,如此往复。
如果我们手工更新transaction_timestamp列,将这个值设置为当前正在执行的大事务的LSN,那么distribution agent就会不读取这个大事务,而是将其跳过了。
下面以一个实例演示一下
环境如下
Publisher: SQL108W2K8R21
Distributor: SQL108W2K8R22
Subscriber: SQL108W2K8R23
图中高亮的publication中包含3个aritcles,ta,tb,tc
其中ta包含18,218,200万数据,然后我们进行了一下操作
在11:00进行了更新语句,
update ta set c=-11
后续陆续对表ta,tb,tc执行一些插入操作
insert tb values(0,0)
insert tc values(0,0)
之后我们启动replication monitor ,发现有很大的延迟,distribution agent一直在传递a)操作产生的数据
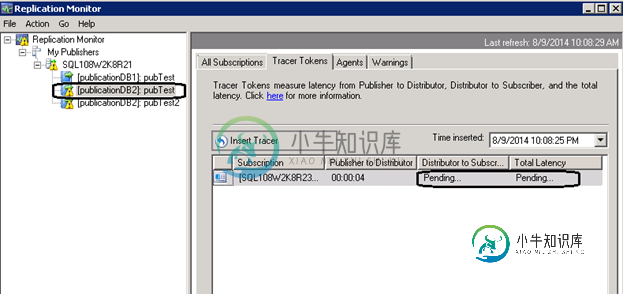
在subscription database中执行下面的语句,得到当前最新记录的事务编号
declare @publisher sysname declare @publicationDB sysname declare @publication sysname set @publisher='SQL108W2K8R22' set @publicationDB='pubdb' set @publication='pubdbtest2' select transaction_timestamp From MSreplication_subscriptions where publisher=@publisher and publisher_db=@publicationDB and publication=@publication
在我的环境中,事务编号为0x0000014900004E9A0004000000000000
返回到distribution database,执行下面的语句,得到紧跟在大事务后面的事务编号. 请将参数替换成您实际环境中的数据。(请注意,如果执行下列语句遇到性能问题,请将参数直接替换成值)
declare @publisher sysname
declare @publicationDB sysname
declare @publication sysname
declare @transaction_timestamp [varbinary](16)
set @publisher='SQL108W2K8R21'
set @publicationDB='publicationdb2'
set @publication='pubtest'
set @transaction_timestamp= 0x0000014900004E9A0004000000000000
select top 1 xact_seqno from MSrepl_commands with (nolock) where xact_seqno>@transaction_timestamp and
article_id in (
select article_id From MSarticles a inner join MSpublications p on a.publication_id=p.publication_id and a.publisher_id=p.publisher_id and a.publisher_db=p.publisher_db
inner join sys.servers s on s.server_id=p.publisher_id
where p.publication=@publication and p.publisher_db=@publicationDB and s.name=@publisher
)
and publisher_database_id =(
select id From MSpublisher_databases pd inner join MSpublications p on pd.publisher_id=p.publisher_id
inner join sys.servers s on pd.publisher_id=s.server_id and pd.publisher_db=p.publisher_db
where s.name=@publisher and p.publication=@publication and pd.publisher_db=@publicationDB
)
Order by xact_seqno
在我的环境中,事务编号为0x0000018C000001000171
在subscription database中执行下面的语句,跳过大的事务。请将参数替换成您实际环境中的数据
declare @publisher sysname declare @publicationDB sysname declare @publication sysname declare @transaction_timestamp [varbinary](16) set @publisher='SQL108W2K8R22' set @publicationDB='pubdb' set @publication='pubdbtest2' set @transaction_timestamp= 0x0000018C000001000171 update MSreplication_subscriptions set transaction_timestamp=@transaction_timestamp where publisher=@publisher and publisher_db=@publicationDB and publication=@publication
执行完成后开启distribution agent job即可。
接下来您就会发现,事务已经成功跳过,ta在订阅端不会被更新,后续的更新会逐步传递到订阅,延迟消失。
-
详细介绍了Redis的事务机制。 MULTI、EXEC、DISCARD 和 WATCH 命令是 Redis 中事务的基础,它们允许将多个命令组合在一起以事物的方式执行。 DISCARD命令用于清除所有先前在一个事务中放入队列的命令,然后恢复正常的连接状态。而当某个事务需要按条件执行时,就要使用WATCH命令将给定的键设置为受监控的。 一个最简单的事务从开始到执行大概会经历以下三个阶段: MULTI
-
本文向大家介绍Spring如何在一个事务中开启另一个事务,包括了Spring如何在一个事务中开启另一个事务的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Spring如何在一个事务中开启另一个事务,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 spring使用@Transactional开启事务,而且该注解使用propagation属
-
本文向大家介绍详解C#之事件,包括了详解C#之事件的使用技巧和注意事项,需要的朋友参考一下 事件:定义了事件成员的类允许通知其他其他对象发生了特定的事情。具体的说,定义了事件成员的类能提供以下功能 1.方法能登记它对事件的关注 2.方法能注销它对事件的关注 3.事件发生时,登记了的方法将收到通知 类型之所以能提供事件通知功能,是因为类型维护了一个已登记方法的列表。事件发生后,类型将通知列表中所有已
-
本文向大家介绍c#中SqlTransaction——事务详解,包括了c#中SqlTransaction——事务详解的使用技巧和注意事项,需要的朋友参考一下 事务处理基本原理 事务是将一系列操作作为一个单元执行,要么成功,要么失败,回滚到最初状态。在事务处理术语中,事务要么提交,要么中止。若要提交事务,所有参与者都必须保证对数据的任何更改是永久的。不论系统崩溃或是发生其他无法预料的事件,更
-
本文向大家介绍Mysql事务处理详解,包括了Mysql事务处理详解的使用技巧和注意事项,需要的朋友参考一下 一、Mysql事务概念 MySQL 事务主要用于处理操作量大,复杂度高的数据。由一步或几步数据库操作序列组成逻辑执行单元,这系列操作要么全部执行,要么全部放弃执行。在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。事务用来管理 insert,update,del
-
问题内容: 我们遇到了适用于多线程的方案。 在主线程中,执行一些逻辑操作并更新数据库,在某种程度上,它将调用另一个服务来更新数据库,该服务在另一个线程中运行。 我们希望两个线程共享同一个事务,这意味着任何一个线程中的任何一个操作都将失败,那么另一个线程中的该操作也将被回滚。 但是工作了几天,我发现一些帖子说JTA不支持多线程。当前我们使用Bitronix作为JTA提供者,有没有人知道Bitroni