
Python提取频域特征知识点浅析

在多数的现代语音识别系统中,人们都会用到频域特征。梅尔频率倒谱系数(MFCC),首先计算信号的功率谱,然后用滤波器和离散余弦变换的变换来提取特征。本文重点介绍如何提取MFCC特征。
首先创建有一个Python文件,并导入库文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt1、首先创建有一个Python文件,并导入库文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt
读取音频文件:
samplimg_freq, audio = wavfile.read("data/input_freq.wav")
提取MFCC特征和过滤器特征:
mfcc_features = mfcc(audio, samplimg_freq)
filterbank_features = logfbank(audio, samplimg_freq)


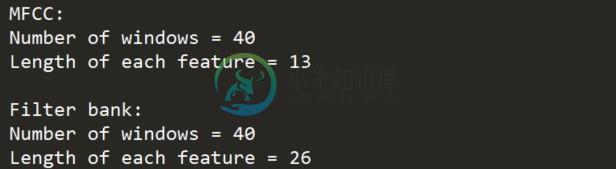
打印参数,查看可生成多少个窗体:
print('\nMFCC:\nNumber of windows =', mfcc_features.shape[0])
print('Length of each feature =', mfcc_features.shape[1])
print('\nFilter bank:\nNumber of windows=', filterbank_features.shape [0])
print('Length of each feature =', filterbank_features.shape[1])
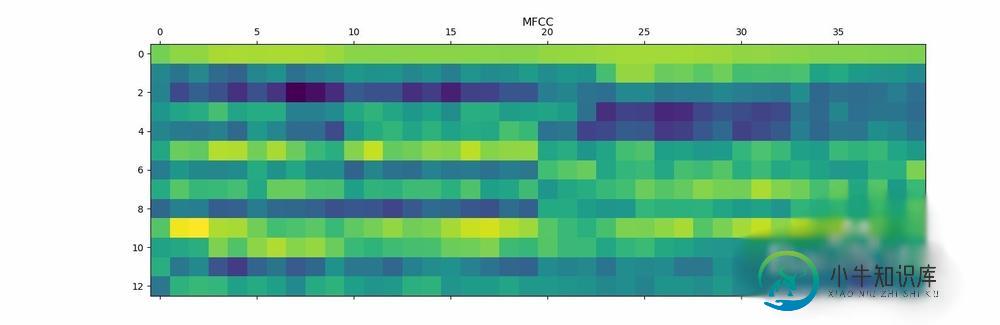
将MFCC特征可视化。转换矩阵,使得时域是水平的:
mfcc_features = mfcc_features.T
plt.matshow(mfcc_features)
plt.title('MFCC')
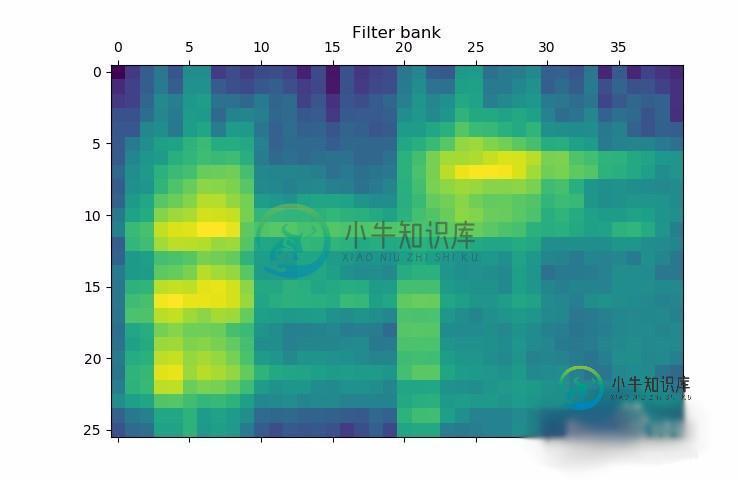
将滤波器组特征可视化。转化矩阵,使得时域是水平的:
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()
-
本文向大家介绍python中count函数知识点浅析,包括了python中count函数知识点浅析的使用技巧和注意事项,需要的朋友参考一下 python中,count函数的作用是进行python中的数量计算。count函数用于统计字符串、列表或元祖中某个字符出现的次数,是一个很好用的统计函数。具体介绍请看本文。 1、count函数 统计列表ls中value元素出现的次数 2、语法 或 3、参数 s
-
Spark特征提取(Extracting)的3种算法(TF-IDF、Word2Vec以及CountVectorizer)结合Demo进行一下理解 TF-IDF算法介绍: 词频-逆向文件频率(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。 词语由t表示,文档由d表示,语料库由D表示。词频TF(t,,d)是词语t在文档d中出现的次数。文件频率D
-
校验者: @if only 翻译者: @片刻 模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。 Note 特征特征提取与 特征选择 有很大的不同:前者包括将任意数据(如文本或图像)转换为可用于机器学习的数值特征。后者是将这些特征应用到机器学习中。 4.2.1. 从字典类型加载特征 类 DictVectorizer 可用于将标准的Py
-
卷积神经网络包括主要特征,提取。以下步骤用于实现卷积神经网络的特征提取。 第1步 导入相应的模型以使用“PyTorch”创建特征提取模型。 第2步 创建一类特征提取器,可以在需要时调用。
-
本文向大家介绍Python实现的特征提取操作示例,包括了Python实现的特征提取操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现的特征提取操作。分享给大家供大家参考,具体如下: 更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧
-
分类变量的特征提取 比如城市作为一个特征,那么就是一系列散列的城市标记,这类特征我们用二进制编码来表示,是这个城市为1,不是这个城市为0 比如有三个城市:北京、天津、上海,我们用scikit-learn的DictVector做特征提取,如下: # coding:utf-8 import sys reload(sys) sys.setdefaultencoding( "utf-8" ) from