
在Nginx中拦截特定用户代理的教程

现代互联网滋生了大量各种各样的恶意机器人和网络爬虫,比如像恶意软件机器人、垃圾邮件程序或内容刮刀,这些恶意工具一直偷偷摸摸地扫描你的网站,干些诸如检测潜在网站漏洞、收获电子邮件地址,或者只是从你的网站偷取内容。大多数机器人能够通过它们的“用户代理”签名字符串来识别。
作为第一道防线,你可以尝试通过将这些机器人的用户代理字符串添加入robots.txt文件来阻止这些恶意软件机器人访问你的网站。但是,很不幸的是,该操作只针对那些“行为良好”的机器人,这些机器人被设计遵循robots.txt的规范。许多恶意软件机器人可以很容易地忽略掉robots.txt,然后随意扫描你的网站。
另一个用以阻挡特定机器人的途径,就是配置你的网络服务器,通过特定的用户代理字符串拒绝要求提供内容的请求。本文就是说明如何在nginx网络服务器上阻挡特定的用户代理。
在Nginx中将特定用户代理列入黑名单
要配置用户代理阻挡列表,请打开你的网站的nginx配置文件,找到server定义部分。该文件可能会放在不同的地方,这取决于你的nginx配置或Linux版本(如,/etc/nginx/nginx.conf,/etc/nginx/sites-enabled/<your-site>,/usr/local/nginx/conf/nginx.conf,/etc/nginx/conf.d/<your-site>)。
server {
listen 80 default_server;
server_name xmodulo.com;
root /usr/share/nginx/html;
....
}
在打开该配置文件并找到 server 部分后,添加以下 if 声明到该部分内的某个地方。
server {
listen 80 default_server;
server_name xmodulo.com;
root /usr/share/nginx/html;
# 大小写敏感的匹配
if ($http_user_agent ~ (Antivirx|Arian) {
return 403;
}
#大小写无关的匹配
if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
return 403;
}
....
}
如你所想,这些 if 声明使用正则表达式匹配了任意不良用户字符串,并向匹配的对象返回403 HTTP状态码。 $http_user_agent是HTTP请求中的一个包含有用户代理字符串的变量。‘~'操作符针对用户代理字符串进行大小写敏感匹配,而‘~*'操作符则进行大小写无关匹配。‘|'操作符是逻辑或,因此,你可以在 if 声明中放入众多的用户代理关键字,然后将它们全部阻挡掉。
在修改配置文件后,你必须重新加载nginx以激活阻挡:
$ sudo /path/to/nginx -s reload
你可以通过使用带有 “--user-agent” 选项的 wget 测试用户代理阻挡。
$ wget --user-agent "malicious bot" http://<nginx-ip-address>
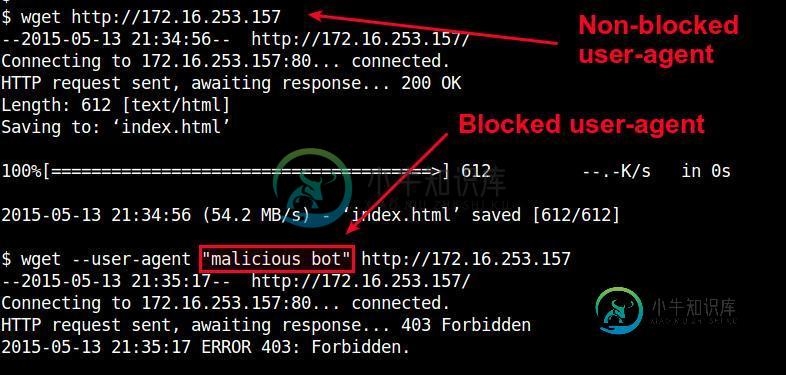
管理Nginx中的用户代理黑名单
目前为止,我已经展示了在nginx中如何阻挡一些用户代理的HTTP请求。如果你有许多不同类型的网络爬虫机器人要阻挡,又该怎么办呢?
由于用户代理黑名单会增长得很大,所以将它们放在nginx的server部分不是个好点子。取而代之的是,你可以创建一个独立的文件,在该文件中列出所有被阻挡的用户代理。例如,让我们创建/etc/nginx/useragent.rules,并定义以下面的格式定义所有被阻挡的用户代理的图谱。
$ sudo vi /etc/nginx/useragent.rules
map $http_user_agent $badagent {
default 0;
~*malicious 1;
~*backdoor 1;
~*netcrawler 1;
~Antivirx 1;
~Arian 1;
~webbandit 1;
}
与先前的配置类似,‘~*'将匹配以大小写不敏感的方式匹配关键字,而‘~'将使用大小写敏感的正则表达式匹配关键字。“default 0”行所表达的意思是,任何其它文件中未被列出的用户代理将被允许。
接下来,打开你的网站的nginx配置文件,找到里面包含 http 的部分,然后添加以下行到 http 部分某个位置。
http {
.....
include /etc/nginx/useragent.rules
}
注意,该 include 声明必须出现在 server 部分之前(这就是为什么我们将它添加到了 http 部分里)。
现在,打开nginx配置定义你的服务器的部分,添加以下 if 声明:
server {
....
if ($badagent) {
return 403;
}
....
}
最后,重新加载nginx。
$ sudo /path/to/nginx -s reload
现在,任何包含有/etc/nginx/useragent.rules中列出的关键字的用户代理将被nginx自动禁止。
-
问题内容: 我知道如何拦截所有请求,但是我只想拦截来自我资源的请求。 有谁知道如何做到这一点? 问题答案: 如果只想拦截来自特定资源的请求,则可以使用可选的action 属性。Angular的文档请参见此处(用法>操作) 的JavaScript Plunker:http ://plnkr.co/edit/xjJH1rdJyB6vvpDACJOT?p=preview
-
我在artemis代理中添加了一个mqtt拦截器,以便拦截mqtt客户端连接: 我的客户端apache paho通过这个端口“WS://0.0.0.0:61614”连接到代理。 我的问题是只截获发布到主题的消息。 为什么不截获连接消息?
-
对资源请求的拦截代理是 Service Worker 的重要功能之一。Service Worker 在完成注册并激活之后,对 fetch 事件的监听就会开始生效,我们可以在事件回调里完成对请求的拦截与改写。下面这个简单的例子演示了如何拦截 http://127.0.0.1:8080/data.txt 的资源请求,并返回固定请求响应的过程: self.addEventListener('fetch'
-
本文向大家介绍使用Nginx做WebSockets代理教程,包括了使用Nginx做WebSockets代理教程的使用技巧和注意事项,需要的朋友参考一下 WebSocket 协议提供了一种创建支持客户端和服务端实时双向通信Web应用程序的方法。作为HTML5规范的一部分,WebSockets简化了开发Web实时通信程序的难度。目前主流的浏览器都支持WebSockets,包括火狐、IE、Chrome、
-
问题内容: 我正在使用Java EE 6和Jboss AS7.1,并尝试使用拦截器绑定(来自jboss网站的示例)。 我有一个InterceptorBinding注解: 拦截器: 还有一个豆: 但是拦截器没有被称为。。。 在编写此代码时将调用拦截器: 谢谢你的帮助。 问题答案: 您是否按照参考示例中的说明启用了拦截器? 缺省情况下,bean档案没有通过拦截器绑定绑定的已启用拦截器。必须通过将侦听器
-
本文向大家介绍Java的Struts2框架中拦截器使用的实例教程,包括了Java的Struts2框架中拦截器使用的实例教程的使用技巧和注意事项,需要的朋友参考一下 1、拦截器小介 拦截器的功能类似于web.xml文件中的Filter,能对用户的请求进行拦截,通过拦截用户的请求来实现对页面的控制。拦截器是在Struts-core-2.2.3.jar中进行配置的,原始的拦截器是在struts-defa